In the previous post, I posed two questions. I’ll answer the second first.
This question considers what would happen if the response function (any response function) were to depend only on a single latent variable. To use the notation of the previous post, I’d write  Here I will be a little more general and allow
Here I will be a little more general and allow  to be multinomial rather than binomial. The model presented in the previous post can then just be written as
to be multinomial rather than binomial. The model presented in the previous post can then just be written as  where with a slight abuse of notation I’m letting
where with a slight abuse of notation I’m letting  denote an indicator vector.
denote an indicator vector.
So it turns out that we can just reduce any choice of  to this construction by rewriting
to this construction by rewriting  For example, in the model presented several posts earlier,
For example, in the model presented several posts earlier,  which means that we can represent this in the more general parameterization as
which means that we can represent this in the more general parameterization as  Thus the answer to the question is a non-starter; the previous post already answered it.
Thus the answer to the question is a non-starter; the previous post already answered it.
The other question asks what would happen if we took the previous post’s model, but made the response a function of 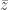 instead of
instead of  In other words,
In other words, 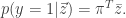 This looks pretty similar (in expectation) to the previous model except that is part of the model now rather than just a result of an expectation. So, if we want to compute
This looks pretty similar (in expectation) to the previous model except that is part of the model now rather than just a result of an expectation. So, if we want to compute ![\mathbb{E}_z[p(y = 1| \vec{z})],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_z%5Bp%28y+%3D+1%7C+%5Cvec%7Bz%7D%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) it works out to be the same. But if we want to compute
it works out to be the same. But if we want to compute ![\mathbb{E}_z[\log p(y = 1 | \vec{z})],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_z%5B%5Clog+p%28y+%3D+1+%7C+%5Cvec%7Bz%7D%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) it’s different. In terms of the original formulation, we are moving the logarithm across the expectation with respect to
it’s different. In terms of the original formulation, we are moving the logarithm across the expectation with respect to  but NOT across the expectation with respect to
but NOT across the expectation with respect to 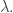
Moving it as such, it does not have a simple closed form solution, so I can’t provide an analytic solution to the error incurred by moving the log inside the expectation. However, I can empirically estimate this by sampling from where each 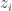 is drawn according to a binomial distribution parameterized by
is drawn according to a binomial distribution parameterized by 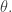 I then compute
I then compute  using this and take the mean over all samples (in this case, 100 samples were used for every point). I compare this value to the value obtained by computing
using this and take the mean over all samples (in this case, 100 samples were used for every point). I compare this value to the value obtained by computing  at the mean over these same samples. This error is what I plot in the attached figure as a function of
at the mean over these same samples. This error is what I plot in the attached figure as a function of
Estimating the loss incurred by moving the log into the expectation.
I produce three series for different values of 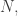 the number of draws from the binomial distribution used to create
the number of draws from the binomial distribution used to create  I chose values of
I chose values of  This corresponds to the red line in the previous post. One thing that is evident is that the error is much smaller. You can think of the previous post’s curve as the
This corresponds to the red line in the previous post. One thing that is evident is that the error is much smaller. You can think of the previous post’s curve as the 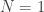 case. As
case. As  increases, the covariance on decreases and the error drops. This is rather comforting. However, for reasonable values of the errors are still rather large: 0.10 may not seem like a lot in log likelihood, but that’s a lot larger that the difference between most techniques!
increases, the covariance on decreases and the error drops. This is rather comforting. However, for reasonable values of the errors are still rather large: 0.10 may not seem like a lot in log likelihood, but that’s a lot larger that the difference between most techniques!


