
When training generative models, we usually optimize parameters to optimize joint likelihood. However, this is in no way (or is it? let me know if you know better) a guarantee that you’ll do better on many real-world benchmarks such as precision/recall. So I wondered, what would happen if you optimized for these quantities?
Let’s take a step back. In a lot of applications (especially information retrieval), what you want is some mechanism (such as a predictive model) of generating scores associated with each possible outcome. And then you measure the loss based on the score of the outcome you wanted versus the score on all other outcomes. For example, let  denote the
denote the  th outcome and
th outcome and  the score of the th outcome. Then our goal is to optimize
the score of the th outcome. Then our goal is to optimize 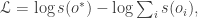 where
where  is the “good” outcome. For example, if we were searching for a needle in a haystack, would be the needle and we want to ensure that the score associated with the needle is much higher than the score associated with the hay.
is the “good” outcome. For example, if we were searching for a needle in a haystack, would be the needle and we want to ensure that the score associated with the needle is much higher than the score associated with the hay.
denote the th outcome and the score of the th outcome. Then our goal is to optimize where is the “good” outcome. For example, if we were searching for a needle in a haystack, would be the needle and we want to ensure that the score associated with the needle is much higher than the score associated with the hay.In the context of the models I’ve been discussing, the “score” is just the probability of a link. The objective then takes the form (over all links of interest):
 where
where  is the set of links of interest. When we use
is the set of links of interest. When we use  as the link probability function, we can evaluate this quantity analytically:
as the link probability function, we can evaluate this quantity analytically:  Here,
Here,  The last sum is could be computationally difficult, except that we can rewrite it as
The last sum is could be computationally difficult, except that we can rewrite it as  where
where  is the total number of possible links and
is the total number of possible links and  The gradient of this whole thing is easy enough to compute and we can throw the whole thing into our favorite optimizer using the log barrier method to ensure that
The gradient of this whole thing is easy enough to compute and we can throw the whole thing into our favorite optimizer using the log barrier method to ensure that  doesn’t run away.
doesn’t run away. So what happens you might wonder? Well, for the data I have it becomes unstable and the probability of linkage when two nodes are at all similar approaches 1 and when they are not it approaches 0. Thus, in practice the log probability becomes a large number minus a large number. The intuition behind why this happens is a little like the intuition behind separation in regression. If, on the balance, any covariate is predictive of the output, then it’s coefficient might as well get shoved to (negative) infinity. Another perspective is by looking at the objective in terms of one covariate (one that governs the current outcome of interest); then  where we have put in the denominator
where we have put in the denominator  other outcomes which have the same response function as the outcome we care about. No matter what we think about those other outcomes, the objective can be optimized by setting the score for all of these outcomes as high as possible.
other outcomes which have the same response function as the outcome we care about. No matter what we think about those other outcomes, the objective can be optimized by setting the score for all of these outcomes as high as possible.
where we have put in the denominator other outcomes which have the same response function as the outcome we care about. No matter what we think about those other outcomes, the objective can be optimized by setting the score for all of these outcomes as high as possible. Meandering theory aside, I wondered what would happen if I tried this to do actual prediction. The table below gives the results (the first two are from a previous table, the last one is the method I’m describing in this post).
| Method | Predictive Log Link Likelihood |
| Maximum likelihood estimate | -11.6019 |
| Arbitrarily set to 4,-3 | -11.4354 |
| Proposed method | -11.3065 |
Wow, epic win using this method. But before we get too excited, we should remember that setting the parameters this way has a discriminative flavor. In particular, the word likelihood, that other thing we care about, actually goes down. In contrast to the “proper” generative approach, here you need to set the parameters differently for each task you want to participate in.

