
Dave and I were recently talking about Asuncion et al.’s wonderful recent paper “On Smoothing and Inference for Topic Models.” One thing that caught our eye was the CVB0 inference method for topic models, which is described as a first-order approximation of the collapsed variational Bayes approach. The odd thing is that this first-order approximation performs better than other, more “principled” approaches. I want to try to understand why. Here’s my current less-than-satisfactory stab:
Let me just lay out the problem. Suppose I want to approximate the marginal posterior over topic assignments 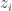


![p(z_i | w) = \mathbb{E}_{p(z_{-i} | w)}[p(z_i | z_{-i}, w)].](https://s0.wp.com/latex.php?latex=p%28z_i+%7C+w%29+%3D+%5Cmathbb%7BE%7D_%7Bp%28z_%7B-i%7D+%7C+w%29%7D%5Bp%28z_i+%7C+z_%7B-i%7D%2C+w%29%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
We can’t compute the expectation analytically, so we must turn to an approximate inference technique. One technique is to run a Gibbs sampler whence we get 

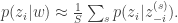
In the case of LDA, this conditional probability is proportional to

where
is the Dirichlet hyperparameter for topic proportion vectors;
is the Dirichlet hyperparameter for the topic multinomials;
-
is the number of times topic
has been assigned to word
-
is the number of times topic
-
is the number of times topic

Note that the above counts do not include the current value of
Instead of the Gibbs sampling approach, we could also approximate the expectation by taking a first order approximation (which we denote 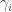
![\mathbb{E}[p(z_i | z_{-i})] \approx \gamma_i \propto \frac{\mathbb{E}[N^{\lnot i}_{wk}] + \eta}{\mathbb{E}[N^{\lnot i}_k] + V \eta} (\mathbb{E}[N^{\lnot i}_{dk}] + \alpha),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bp%28z_i+%7C+z_%7B-i%7D%29%5D+%5Capprox+%5Cgamma_i+%5Cpropto+%5Cfrac%7B%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_%7Bwk%7D%5D+%2B+%5Ceta%7D%7B%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_k%5D+%2B+V+%5Ceta%7D+%28%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_%7Bdk%7D%5D+%2B+%5Calpha%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
where the expectations are taken with respect to 

![\mathbb{E}[N^{\lnot i}_k] = \mathbb{E}[\sum_{j \ne i} z_{jk}] = \sum_{j \ne i} \mathbb{E}[z_{jk}] = \sum_{j \ne i} p(z_j) \approx \sum_{j \ne i} \gamma_j.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_k%5D+%3D+%5Cmathbb%7BE%7D%5B%5Csum_%7Bj+%5Cne+i%7D+z_%7Bjk%7D%5D+%3D+%5Csum_%7Bj+%5Cne+i%7D+%5Cmathbb%7BE%7D%5Bz_%7Bjk%7D%5D+%3D+%5Csum_%7Bj+%5Cne+i%7D+p%28z_j%29+%5Capprox+%5Csum_%7Bj+%5Cne+i%7D+%5Cgamma_j.&bg=ffffff&fg=333333&s=0&c=20201002)
Thus, the solution to this approximation is exactly the CVB0 technique described in the paper. Note that I never directly introduced the concept of a variational distribution! CVB0 is simply a first-order approximation to the true expectations; in contrast, the second-order CVB approximation is an approximation of the variational expectations. So maybe that’s the answer to the puzzle: sometimes a first-order approximation to the true value is better than a second-order approximation to a surrogate objective.
Does anyone have any other explanations?


