
In a post a while ago, I wondered how much info about the band one could glean just by looking at the name. I mean, shouldn’t it be obvious that a band named “Trauma” should be heavy metal?
This was the genesis of a collaboration between me and Matt Hoffman. We wanted to see if you could improve genre prediction using the names of the bands. Unfortunately, neither of us had enough time to really get this project going, but I thought I’d share what results we did get in hopes that someone else will pick up the torch.
To start off, we need a large training set of band/genre mappings. We opted for the DBPedia Infobox mine that you can find at infochimps. (For those who don’t know, they’ve done some awesome data mining to grab all the structured info from Wikipedia infoboxes). I did some cleaning up and have put up the list of artists and genres (the artist in each line of the first file is associated with the genres on the corresponding line of the second file).
You might have noticed that Wikipedia is pretty crazy when it comes to genre definitions (because god forbid we confuse Melodic Death Metal and Power Metal). This craziness makes it hard to map the artists to any canonicalized genre set (such as CAL-500). I tried a bunch of techniques to do this canonicalization (including doing my own crawl of Wikipedia with all sorts of heuristics). None of it worked very well for mapping genres to a canonicalized set, but it did let me make a really cool graph of connections between genres. Eventually, we came to the conclusion that we needed human judgments. We got mechanical turkers to label Wikipedia genres with CAL-500 genres. Those results are here.
With that training set in place, I decided to explore the data to see if there truly were correlations between substrings of artist names and genres. The plot below shows the prevalence in each genre of artists containing “death” (red) or “boyz” (blue) in their name. The green dots show the overall distribution of genres among artists in Wikipedia.

The graph shows that bands containing “death” in their name are much more likely to be Rock, Alternative, Metal/Hard Rock, or Alternative. Conversely, they are less likely to be Jazz, Hip-Hop, or Soul. In contrast, bands containing “boyz” in their name are overwhelmingly Hip-Hop. This confirmed my intuition and seemed promising to me, so we went ahead and developed a classifier for the CAL-500 data set. The techniques we tried were:
- names (corrLDA)– the correlated topic model fit to the Wikipedia data. Predictions use only names.
- names (NB) – naive Bayes fit to the Wikipedia data. Predictions use only names.
- names (LR) – logistic regression fit to the Wikipedia data. Predictions use only names.
- baseline – Predictions use the baseline frequency of genres on Wikipedia. Predictions do not use any information about the instances.
- svm – SVM fit using MFCC features. Predictions use both names and audio.
- svm + names (corrLDA) – SVM fit using MFCC features plus the results of names (corrLDA). Predictions use both names and audio.
- svm + names (NB)– SVM fit using MFCC features plus the results of names (NB). Predictions use both names and audio.
- svm + names (LR)– SVM fit using MFCC features plus the results of names (LR). Predictions use both names and audio.
The plot below shows the precision-recall for each of these techniques. As you can see, it’s not very promising. The SVM will outclass any technique which uses the name along; otherwise all of the name techniques look about the same. It looks like we might get a small bump by combining SVM with names (LR) but it’s hard to tell.

But precision-recall may not be the right metric. After all, pop and rock are so frequent that you will probably predict pop for every single item in the test set before you even make any other prediction. Something which is perhaps more meaningful is to look at the rank of the correct labels on a per-test-instance level; the lower the rank, the better the model is at making predictions. Boxplots of the ranks are given below.
![]()
We see slightly different patterns when we look at the ranks. Without using any audio data, the naive Bayes technique performs best and manages to get a non-trivial bump beyond the baseline. When audio is included, the names add something, but not much. Interestingly, the names (LR) technique which looked like it might help us at precision-recall actually does a bit worse when you look at the rank. On the other hand, SVM + names (corrLDA) has the same median as SVM, but manages to do a better job at some of the difficult-to-predict cases, leading to a smaller interquartile range.
In sum, names give us something — unfortunately, it’s not a whole lot.
![\mathbb{E}_{z \sim p(z | x)}[f(z)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bz+%5Csim+p%28z+%7C+x%29%7D%5Bf%28z%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where  represents some distribution on hidden variables over which you are trying to compute a function,
represents some distribution on hidden variables over which you are trying to compute a function,  . For the usual reasons, it’s intractable to compute this exactly, so you’re going to use a sampler. Let’s assume
. For the usual reasons, it’s intractable to compute this exactly, so you’re going to use a sampler. Let’s assume samples from the sampler costs some amount, say
samples from the sampler costs some amount, say  .
.
![\mathbb{E}_{z \sim \hat{p_n}(z | x)}[f(z)] \rightarrow \mathbb{E}_{z \sim p(z | x)}[f(z)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bz+%5Csim+%5Chat%7Bp_n%7D%28z+%7C+x%29%7D%5Bf%28z%29%5D+%5Crightarrow+%5Cmathbb%7BE%7D_%7Bz+%5Csim+p%28z+%7C+x%29%7D%5Bf%28z%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where  is the distribution obtained by using
is the distribution obtained by using ![\ell = R(n) + |\mathbb{E}_{z \sim \hat{p_n}(z | x)}[f(z)] - \mathbb{E}_{z \sim p(z | x)}[f(z)]|](https://s0.wp.com/latex.php?latex=%5Cell+%3D+R%28n%29+%2B+%7C%5Cmathbb%7BE%7D_%7Bz+%5Csim+%5Chat%7Bp_n%7D%28z+%7C+x%29%7D%5Bf%28z%29%5D+-+%5Cmathbb%7BE%7D_%7Bz+%5Csim+p%28z+%7C+x%29%7D%5Bf%28z%29%5D%7C&bg=ffffff&fg=333333&s=0&c=20201002) , that is, how far off our sampled estimate is from the truth, plus the cost of obtaining those samples. Using Hoeffding, we can bound the loss
, that is, how far off our sampled estimate is from the truth, plus the cost of obtaining those samples. Using Hoeffding, we can bound the loss  with probability
with probability 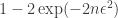 . This expression gives you something to think about when you're trying to decide how many samples to take — more samples loosen the bound but increase its probability.
. This expression gives you something to think about when you're trying to decide how many samples to take — more samples loosen the bound but increase its probability. 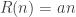 , you might want to choose
, you might want to choose , which gives you a loss of
, which gives you a loss of  with probability
with probability  .
. 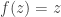 . The curves show the loss,
. The curves show the loss,  for various choices of the cost parameter
for various choices of the cost parameter  as a function of the number of samples. The dots show the chosen values of
as a function of the number of samples. The dots show the chosen values of 

