
I had a discussion the other day about using the weights returned by boosting to do outlier detection. That is to say, the examples with high weight are hard to fit and are therefore likely to be mislabeled/outliers. So why not find some way of automatically ignoring these instances?
I know that BBM already magically does something along these lines, but I was wondering if there were some simple fudges for AdaBoost which would also do this. So I decided to run a quick experiment to see what would work. To set up the data, I randomly drew 100 points from 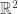
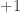



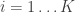

For the weak hypotheses I chose the set of circles (of arbitrary radius) which predict either +1 or -1 in their interior and abstain (i.e., predict 0) on their exterior. Since the true labels can be represented as a linear combination of weak hypotheses in principle it should be easy for boosting to recover drive the training down to 0 were it not for the noisy points. Typically AdaBoost will spend a lot of effort trying to fix up these points with little benefit with respect to generalization error.
Below I describe a couple of methods for finding and ignoring these points during the boosting process. For each I include a plot of the set of weak hypotheses after each iteration (blue circles), along with the predictions made by the combined hypothesis on each of the training instances (purple = +, green = -). Below each plot I also indicate the error on the entire training set (first number) along with the error on the non-noisy, correctly labeled points (second number) since we presumably don’t want to match the noisy points too closely.
- Stock AdaBoost – Nothing special here. This is just plain-jane AdaBoost. It does a pretty good job of driving down the training error (0.11 after 11 iterations). But the hypothesis found by AdaBoost is a rather complex combination of many circles that does not bear that much resemblance to the generating hypothesis. Also note that when the noise is removed, the error at the end is 0.07. Not so good when considering that this number could be zero after two or three iterations.
- AdaBoost /w thresholding – Here I again run stock AdaBoost except that the distribution shown to the weak learner ignores all points whose weight exceeds some threshold. Precisely, let
denote the distribution over training examples which AdaBoost maintains internally. Then the distribution the weak learner sees is
. Here, the combined hypothesis is much simpler consisting essentially of just four circles. The predictions made by this technique really aren’t any worse than regular AdaBoost (0.12 vs 0.11 on the full training set, 0.07 in both cases on the de-noised set). So it seems like doing this is not a completely terrible idea; you make about the same predictions but with much simpler rules.
- AdaBoost /w trimming – Here, once again, we run AdaBoost except this time the distribution shown to the weak learner excludes the 10% of points with the highest mass. That is, let
be the rank of a training example, where
denotes the total number of training examples. Then the distribution shown to the weak learner is
(with some fudging I won’t get into here to break ties). The rules found by this method are unfortunately not that uncomplicated. And while some of the circles are vaguely in the spot they should be, in large part they’re all over the place. But what’s interesting here is that while the error on the training set is about the same as with the other techniques (0.12), the error on just the non-noisy ones is (0.03). So in fact, this method does the best job, in some sense, of ignoring the points which are noisy.
Practically speaking, I think I’d go with AdaBoost /w trimming as an easy approach to getting rid of label noise. Has anyone out there tried this before?
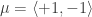 and variance
and variance 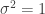 . Let’s also set the mixture components to be
. Let’s also set the mixture components to be  . This gives the following as the density of our distribution:
. This gives the following as the density of our distribution: 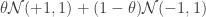 . I’ve conveniently plotted this distribution for you
. I’ve conveniently plotted this distribution for you  drawn from the density. In this case, let’s focus on computing the posterior density of
drawn from the density. In this case, let’s focus on computing the posterior density of  :
: 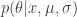 . We can apply Bayes’ rule to rewrite this as
. We can apply Bayes’ rule to rewrite this as 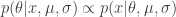 , which is not too hard to compute. The problem is hidden in that proportionality — we don’t know what the proportionality constant should be.
, which is not too hard to compute. The problem is hidden in that proportionality — we don’t know what the proportionality constant should be. , where
, where  are some Dirichlet parameters you learn as part of the variational inference procedure.
are some Dirichlet parameters you learn as part of the variational inference procedure. . I can try to guesstimate that unknown proportionality constant
. I can try to guesstimate that unknown proportionality constant  . Note that for this estimate of
. Note that for this estimate of  , there’s no guarantee that
, there’s no guarantee that  integrates to one, but if
integrates to one, but if  happens to be equal to the true posterior, then
happens to be equal to the true posterior, then  . For convenience, I’m going to call this approximation to the posterior the scaled true posterior.
. For convenience, I’m going to call this approximation to the posterior the scaled true posterior. observations). The variational approximation is given in black, and the scaled true posterior is given in purple. The green horizontal line shows the actual ratio of draws from the first mixture component for the given observations. The blue line shows the mode of the scaled true posterior (and therefore also the true posterior), which can be found with some straightforward numerical optimization. The reference point
observations). The variational approximation is given in black, and the scaled true posterior is given in purple. The green horizontal line shows the actual ratio of draws from the first mixture component for the given observations. The blue line shows the mode of the scaled true posterior (and therefore also the true posterior), which can be found with some straightforward numerical optimization. The reference point  . Then we can compute the ratio of the posterior probabilities for these two points exactly since the normalization cancels out:
. Then we can compute the ratio of the posterior probabilities for these two points exactly since the normalization cancels out:  . It seems reasonable that the Dirichlet distribution should preserve the ratio between these two distinguished points, so we’ll make the first constraint
. It seems reasonable that the Dirichlet distribution should preserve the ratio between these two distinguished points, so we’ll make the first constraint  .
.
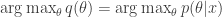 .
.
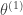 to be the mode of the true posterior and
to be the mode of the true posterior and 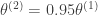 . I performed this “inference” procedure; the result is plotted as the cyan line in the above plots. Once again, we can use this approximation to create a scaled true posterior; this scaled true posterior is plotted as the red line.
. I performed this “inference” procedure; the result is plotted as the cyan line in the above plots. Once again, we can use this approximation to create a scaled true posterior; this scaled true posterior is plotted as the red line.
