
What would we do without the train/test paradigm? It gives us a convenient way of saying “Aha, I’m better than X et al. by 5%!” But rarely do we actually get data which has been partitioned into train/test by a higher power; instead we get a bunch of labeled data which we have to split in twain (or variations thereof if we wanted to be more sophisticated and do x-validation, bootstrapping, etc.).
Now this is usually not too big an issue. We just uniformly randomly select elements from the labeled data to construct our training set. This gives us training and test sets with approximately the same distributional characteristics and all is well with the world.
This becomes considerably more challenging (or interesting, depending on your point of view) when we have network data. The whole point of modeling data along with the relationships between them is to remove the typical i.i.d. assumptions. This means that drawing i.i.d. samples from the set of documents to construct the training/test sets disregards the very thing you are trying to model (and which you therefore believe to be important).
How you actually want to construct your train/test split will probably depend in part on your application and the constraints you have on how data is obtained. But we’d like to believe our algorithms do (relatively) as well no matter how the train/test split is done. Because of that (and limited resources) we tend to evaluate our models only on one such splitting scheme. In this post, I want to see if this actually matters.
More precisely, I want to consider what happens when you want to predict links. Because of sampling or what have you, your model is only able to see a subset of the links in the network (the train set). The model’s goal is to infer from these seen links the remaining hidden links (the test set).
Here’s my experimental set up. I’m going to imagine that I’m writing a paper and I want to compare two models. One is a naive model (NM) and the other is a really naive model (RNM). The specifics of these models aren’t too important (and looking at the results there’s a good chance you’ll be able to guess what they are). And I’m going to try doing the evaluation with two different train/test splitting methods. The first uses a “Bernoulli” hold out method. That is, each edge is allocated independently to the test set with probability 

So now we have two (plausible) ways of constructing train/test splits but which look potentially very different. I’m going to “evaluate” my two models by computing the mean log likelihood of the held-out links for 10 chosen graphs using the aforementioned sampling schemes. For these experiments, I chose 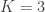
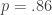
Results are presented below (standard deviations are in red).
Predictive power of two models on two holdout methods
RNM performs the same no matter how you select the hold-out graphs (and the standard deviations are zero, which should give you a pretty good idea of what RNM is). NM as we’d expect performs (significantly) better no matter what sampling method is used. However, when survey sampling is used, NM performs considerably better than NM on Bernoulli. In fact, the difference between NM and RNM on Bernoulli is paltry compared to the difference on survey.
What this means is that the value proposition between RNM and NM is very different depending on how your data is being collected. And the conclusions we draw about models on one sampling method might not be easily applied to another.

