
Not too long ago John Langford stopped on by and gave a fascinating talk. There were a lot of take-aways from the talk but here’s one that really got my noodle going: A lot of times we get really high-dimensional data (say text) and we want to use it to make some prediction. The high-dimensionality makes the problem intractably difficult, in part because of the curse, and in part because high-dimensional feature spaces lead to high-dimensional parameter spaces which is computationally (and space) taxing.
So what do we do? Dimensionality reduction or feature selection. A lot of effort has gone into doing these well (some popular ones these days are LDA and L1 regularization). JL came up with another way of doing dimensionality reduction: he ignores hash conflicts. At first blush this seems silly: you’ll get a form of dimensionality reduction wherein different features will be additively combined in some arbitrary way. But his results show that this actually works quite well. I’m not entirely sure why, but that got me thinking: are there simple ways of reducing feature spaces that make for very good !/$ propositions? I decided to find out by running some experiments on a scale/domain I’m a little more familiar with.
Here’s the experimental setup: I took the Cora data set (thanks to LINQS.UMD for making a munged version of this data available) which is a database of scientific papers each one with a subject categorization. In order to keep things simple, my goal will be to predict whether or not a paper is labeled as “Theory.” I’ll try to make these predictions using binary word features (i.e., the presence or absence of a word in a paper’s abstract). I’ll take these features and put them through a logistic regression model with a little bit of an L2 penalty for good measure (n.b. I also tried an SVM; the results are about the same but a little worse). My data’s been cleaned up but there are still around 1.5k features and only 2.7k data points. This is less than ideal because 1.) the dimensionality to data ratio is not too good, and 2.) storing that matrix is still pretty taxing for my poor laptop.
What I want to do is reduce the number of features to a fixed size 

- random – Uniformly randomly select
- corr – Select the
- cream – Select the
- crust – Like “cream,” except skip the first
features, where
is the dimensionality of the feature space. These are the”crust” features, i.e., those that are too frequent or not frequent enough to carry much information.
- merge – Randomly additively combine features until there are just
Here’s the pretty dotchart (the red line is how well you’d do using random guessing) of the 0-1 error estimated using 10 bootstrap replications:
Predictive performance using different feature selection mechanisms.
A few things that surprised me:
- You don’t really need that many features. Using 50 features doesn’t really do substantially worse than 200 if you use corr.
- Corr was just something I threw together on the fly; I really didn’t expect it to work so well and I haven’t actually used it in practice. I guess I should start.
- Cream does better than crust. Crust was motivated by the fact that when you put data into topic models like LDA, you get better looking topics when you remove overly-frequent words (since they tend to trickle to the top of every topic). I guess good looking topics don’t necessarily make for good predictions. Food for thought.
- Random does poorly as one might expect.
- Merge is just about as bad as random. I don’t know how to reconcile this with what I said at the outset except to that 1.) merge is not necessarily combining features the exact same way a hash would 2.) different features 3.) different number of features 4.) different amounts of data 5.) different data sets 6.) a different classifier.
Ok, so the data didn’t show me what I was hoping and half expecting to see. Chalk it up to different strokes for different domains. But I did find something that, while obvious in retrospect, will probably be useful going forward.
 , draw
, draw  ;
;
 :
:
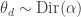 ;
;
 :
:
 ;
;
 .
.
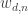 ; the rest of the variables are hidden from us. Now the story usually says that what we need to do is perform posterior inference, that is, determine the distribution over the hidden variables (
; the rest of the variables are hidden from us. Now the story usually says that what we need to do is perform posterior inference, that is, determine the distribution over the hidden variables ( and sometimes
and sometimes  ) given the observations. People have come up with a bunch of ways of doing this like MCMC and variational inference.
) given the observations. People have come up with a bunch of ways of doing this like MCMC and variational inference. ; however we typically don’t care about is
; however we typically don’t care about is 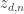 .
. 
 . We can expand the probability for a single word
. We can expand the probability for a single word  . The portions of the prior term which are relevant are
. The portions of the prior term which are relevant are  .
. 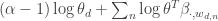 . Now the solution is perhaps not entirely trivial but we can just plug this into a standard optimizer with adequate constraints to solve for the optimal
. Now the solution is perhaps not entirely trivial but we can just plug this into a standard optimizer with adequate constraints to solve for the optimal  and I set the vocabulary size (i.e., the length of each
and I set the vocabulary size (i.e., the length of each  to 2000. Using these hyperparameters I followed the generative process to generate
to 2000. Using these hyperparameters I followed the generative process to generate  .
.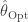 . I also plugged this data set into LDA-C which performs variational inference. LDA-C estimates the posterior distribution; from its estimates I compute the
. I also plugged this data set into LDA-C which performs variational inference. LDA-C estimates the posterior distribution; from its estimates I compute the  . Let me emphasize that both methods are given the true value of the other parameters:
. Let me emphasize that both methods are given the true value of the other parameters: 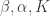 .
. 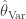 for each document as a function of the number of words in that document. The plot is
for each document as a function of the number of words in that document. The plot is  time and which is perfectly parallelizable — that is, I can split the program up into
time and which is perfectly parallelizable — that is, I can split the program up into  tasks and the latency for the program will be
tasks and the latency for the program will be 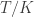 .
. .
.  . Again, it’s clear that you should just parallelize the hell out of your program and eventually your latency will approach
. Again, it’s clear that you should just parallelize the hell out of your program and eventually your latency will approach  . Now each subtask will take a different amount of time; since I’m concerned with the latency, the metric I want to optimize is
. Now each subtask will take a different amount of time; since I’m concerned with the latency, the metric I want to optimize is 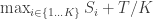 over
over  part of the equation, but on the other, it increases the number of draws of
part of the equation, but on the other, it increases the number of draws of  and therefore the expected maximum value.
and therefore the expected maximum value. is given by
is given by 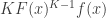 where
where  is the cumulative distribution function (There’s a more general form for the
is the cumulative distribution function (There’s a more general form for the  th order statistic).
th order statistic). , where
, where 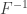 is the inverse cdf (or quantile) function. For almost all distributions this expression cannot be computed analytically (The uniform distribution being the notable exception).
is the inverse cdf (or quantile) function. For almost all distributions this expression cannot be computed analytically (The uniform distribution being the notable exception).  , the analytical solution to the expected maximum value is
, the analytical solution to the expected maximum value is  . This leads to a quadratic polynomial as the solution of the original problem. Without loss of generality, let
. This leads to a quadratic polynomial as the solution of the original problem. Without loss of generality, let 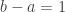 . Then the optimal value of
. Then the optimal value of  . Note that when
. Note that when  the roots are negative, i.e., one should set
the roots are negative, i.e., one should set 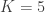 . Also, the different performance for different values of
. Also, the different performance for different values of 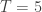 if you spend 5 times as many resources, you’ll go almost twice as fast. Is that a worthwhile investment? When
if you spend 5 times as many resources, you’ll go almost twice as fast. Is that a worthwhile investment? When  you almost definitely don’t want to parallelize at all.
you almost definitely don’t want to parallelize at all.
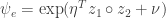
![\mathbb{E}_q[\log \psi(z_1, z_2)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_q%5B%5Clog+%5Cpsi%28z_1%2C+z_2%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) where the expectation is taken over
where the expectation is taken over  and
and ![\mathbb{E}_q[z_i] = \phi_i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_q%5Bz_i%5D+%3D+%5Cphi_i&bg=ffffff&fg=333333&s=0&c=20201002) . If we expand the equation using
. If we expand the equation using  , this amounts to computing
, this amounts to computing ![\eta^T \phi_1 \circ \phi_2 + \nu - \mathbb{E}_q[\log (1 + \exp(\eta^T z_1 \circ z_2 + \nu))]](https://s0.wp.com/latex.php?latex=%5Ceta%5ET+%5Cphi_1+%5Ccirc+%5Cphi_2+%2B+%5Cnu+-+%5Cmathbb%7BE%7D_q%5B%5Clog+%281+%2B+%5Cexp%28%5Ceta%5ET+z_1+%5Ccirc+z_2+%2B+%5Cnu%29%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This latter term is intractable to compute exactly, so we turn to approximation.
. This latter term is intractable to compute exactly, so we turn to approximation. . This is equivalent to approximating the function inside the expectation with a first order Taylor approximation centered around the mean. Because of convexity, this approximation is a tangent line which forms a lower bound on the function (see graph below). Unfortunately, this is the wrong bound for variational inference; there the quantity we are computing is supposed to be a lower bound which means that the bound on the partition function of the link probability function needs to be an upper bound. That was a mouthful, and things seem grim but as it turns out this approximation is rather good since most of the points lie near the mean.
. This is equivalent to approximating the function inside the expectation with a first order Taylor approximation centered around the mean. Because of convexity, this approximation is a tangent line which forms a lower bound on the function (see graph below). Unfortunately, this is the wrong bound for variational inference; there the quantity we are computing is supposed to be a lower bound which means that the bound on the partition function of the link probability function needs to be an upper bound. That was a mouthful, and things seem grim but as it turns out this approximation is rather good since most of the points lie near the mean.
 . This upper bound is also depicted in the figure below. But also note that if we set
. This upper bound is also depicted in the figure below. But also note that if we set  and
and  then this expression becomes
then this expression becomes  which has the exact same functional form as
which has the exact same functional form as ![\mathbb{E}_q[\psi_e(z_1, z_2)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_q%5B%5Cpsi_e%28z_1%2C+z_2%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Thus, using this upper bound reduces to using
. Thus, using this upper bound reduces to using 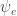 !
! and vocabulary item
and vocabulary item  , draw topic probabilities
, draw topic probabilities  .
.
 .
.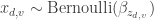 .
. and we observe each document’s binary vector
and we observe each document’s binary vector  .
.
