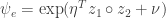When deciding when a link between two documents should exist, we need to define a function of the covariates which we call a link probability function. We have looked at many candidate functions but concentrated on two such functions:
Recently, I saw a new connections between the two functions. This connection exists in the context of variational inference. One of the terms we must compute in variational inference is ![\mathbb{E}_q[\log \psi(z_1, z_2)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_q%5B%5Clog+%5Cpsi%28z_1%2C+z_2%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) where the expectation is taken over
where the expectation is taken over  and
and ![\mathbb{E}_q[z_i] = \phi_i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_q%5Bz_i%5D+%3D+%5Cphi_i&bg=ffffff&fg=333333&s=0&c=20201002) . If we expand the equation using
. If we expand the equation using  , this amounts to computing
, this amounts to computing ![\eta^T \phi_1 \circ \phi_2 + \nu - \mathbb{E}_q[\log (1 + \exp(\eta^T z_1 \circ z_2 + \nu))]](https://s0.wp.com/latex.php?latex=%5Ceta%5ET+%5Cphi_1+%5Ccirc+%5Cphi_2+%2B+%5Cnu+-+%5Cmathbb%7BE%7D_q%5B%5Clog+%281+%2B+%5Cexp%28%5Ceta%5ET+z_1+%5Ccirc+z_2+%2B+%5Cnu%29%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This latter term is intractable to compute exactly, so we turn to approximation.
. This latter term is intractable to compute exactly, so we turn to approximation.
In previous posts, I primarily explored using the approximation  . This is equivalent to approximating the function inside the expectation with a first order Taylor approximation centered around the mean. Because of convexity, this approximation is a tangent line which forms a lower bound on the function (see graph below). Unfortunately, this is the wrong bound for variational inference; there the quantity we are computing is supposed to be a lower bound which means that the bound on the partition function of the link probability function needs to be an upper bound. That was a mouthful, and things seem grim but as it turns out this approximation is rather good since most of the points lie near the mean.
. This is equivalent to approximating the function inside the expectation with a first order Taylor approximation centered around the mean. Because of convexity, this approximation is a tangent line which forms a lower bound on the function (see graph below). Unfortunately, this is the wrong bound for variational inference; there the quantity we are computing is supposed to be a lower bound which means that the bound on the partition function of the link probability function needs to be an upper bound. That was a mouthful, and things seem grim but as it turns out this approximation is rather good since most of the points lie near the mean.
But why not construct an upper bound? This is possible because the function is convex and because the covariates’ range is bounded. The hyperplane which intersects the function at the covariates’ bounds is an upper bound for the function. If we apply this approximation, the expectation expands into 
 . This upper bound is also depicted in the figure below. But also note that if we set
. This upper bound is also depicted in the figure below. But also note that if we set  and
and  then this expression becomes
then this expression becomes  which has the exact same functional form as
which has the exact same functional form as ![\mathbb{E}_q[\psi_e(z_1, z_2)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_q%5B%5Cpsi_e%28z_1%2C+z_2%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Thus, using this upper bound reduces to using
. Thus, using this upper bound reduces to using 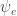 !
!
Two bounds on the link probability function
Thus, rather than considering two link probability functions, it is perhaps better to think of two approximations to a single link probability function. This way of thinking also sheds some light on why perhaps tends to perform better than . Even though the lower-bound approximation is “better” in the sense that it is closer to the true value of the expectation, the bound is in the wrong direction for variational inference. Maybe “cowboy” variational doesn’t work all that well after all.