
A friend of mine recently posed a problem which seems at first blush quite simple but turns out to be quite interesting. Suppose you have a program which takes 

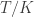
So I can make the latency arbitrarily small by taking 
So why wouldn’t you ever just set 

But what if the startup cost were random? Let the startup cost be drawn from some probability distribution 
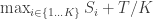
Now there’s a cool tradeoff involved in parallelization: one the one hand, splitting a task reduces the 

It turns out that the solution to this problem leads down a huge rabbit hole involving order statistics, sample maxima, and extreme value statistics. Here are some highlights:
- The probability distribution of the maximum value in a sample of
is given by
where
is the cumulative distribution function (There’s a more general form for the
th order statistic).
- The expected value of the maximum (drawn according to the procedure above) is
, where
is the inverse cdf (or quantile) function. For almost all distributions this expression cannot be computed analytically (The uniform distribution being the notable exception).
- When
, the analytical solution to the expected maximum value is
. This leads to a quadratic polynomial as the solution of the original problem. Without loss of generality, let
. Then the optimal value of
. Note that when
the roots are negative, i.e., one should set
- When
. Also, the different performance for different values of
if you spend 5 times as many resources, you’ll go almost twice as fast. Is that a worthwhile investment? When
you almost definitely don’t want to parallelize at all.
Ok, so it seemed like a simple little problem at first, but it turns out that something as straightforward sounding as parallelization can lead to some pretty interesting analysis.

