
You know, I’ve always taken it for granted that what we want to do is probabilistic inference but lately I’ve been thinking more about what we really want and how to get there.
To illustrate my point, consider our dear friend LDA. For the uninitiated, let me write down the generative process for this Bayesian mixture model of discrete data:
- For
, draw
;
- For
:
- Draw
;
- For
:
- Draw
;
- Draw
.
- Draw
- Draw
We only observe 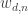


But in fact what we often care about is the mode. Just look at the way practitioners actually use these things. A typical MCMC experiment will run the updates for a hundred iterations or so, look at the final state of the parameters (under the assumption that we’ve found the mode) and then put a pretty picture of this final state in the paper.
If that’s what we actually want, why bother with the rest? Put another way, our goal is to maximize the joint likelihood of the data and the parameters we care about. One parameter we typically care about is 
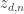
With these facts guiding us, we can write out the optimization problem for a particular document as 



The objective function, in total then, is 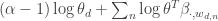
So how well does it do? To test this I generated a synthetic data set using what I felt were fairly typical hyperparameters: 



I then used the procedure above to estimate optimal values of 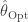
mode mean using 
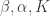
With these estimates of 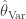
So what we’ve got here is a fairly fast and easy way of finding some kind of “mode” for LDA. Although the modes found by the two techniques aren’t really maximizing the same thing, they both tend to do equally well at recovering the true value of the parameters. So why not just optimize?
P.S. If anybody is actually reading this, and has tried doing optimization with constraints of this sort, we should trade war stories.

