
One of the things people learn during downturns is that it’s actually possible to look ab fab without spending a whole lot of money. Let’s try to apply the same enterprising spirit to posterior inference on mixture models.
Today we’ll consider a simple mixture of two Gaussians, with means set at 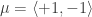
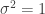

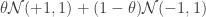
Now most problems in life come down to performing posterior inference, i.e., determining the distribution over the aforementioned parameters given some observations 

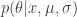
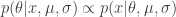
So how do we get around this? Many people like MCMC, but around these parts, we have a lot of folks who use approximate variational inference. The idea behind approximate variational inference is to find a distribution which is “close” to the true posterior. Now I don’t want to get bogged down by details (search Google for “jordan 1999 variational inference” if you really want to know them), but one way of doing this approximates the desired posterior distribution by a Dirichlet distribution, 

Variational inference doesn’t really guarantee all that much about the approximation you find. The usual folk wisdom is that variational inference does an ok job of finding some of the marginal modes, but underestimates the variance (to be fair, you could say the same thing about MCMC). Now I want to see how good my inference procedure turned out to be. How might I go about that? Well, suppose I have a reference point, say 





The big plot of all the approximations
I’ve plotted what this approximation looks like for different numbers of draws from the density (i.e., the posterior given 
Two quick observations. One, the modes (of the black and purple lines) tend to line up pretty well, except when the number of observations is really small. Two, the scaled true posterior tends to be a little bit fatter than the variational approximation which means that the variational approximation is indeed underestimating the variance. Now when faced with the discrepancy between the black and purple lines, a question lingers in my mind: how much of the difference is because of the fitting procedure (i.e., the objective we optimize and how we optimize it), and how much is due to the fact that
we’re choosing to represent the posterior with a Dirichlet distribution rather than some other distribution?
Well, let’s answer this question by trying to fit the Dirichlet distribution some other way instead. Our Dirichlet distribution has two free parameters, so we just need to find two constraints to fit them. Here’s what I decided to go with:
- Choose two points, say
. Then we can compute the ratio of the posterior probabilities for these two points exactly since the normalization cancels out:
. It seems reasonable that the Dirichlet distribution should preserve the ratio between these two distinguished points, so we’ll make the first constraint
.
- It also seems reasonable to ensure that the mode of the approximation has the same mode as the true posterior:
.
It turns out that these constraints make for a simple system of linear equations. Naturally, one can also add more ratio constraints in the more general case. I found it helpful to choose 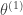
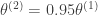
As you can see, the red line and cyan lines line up almost perfectly. Thus we’ve got a fantastic estimate of the posterior distribution. And all we had to do was to 1.) find the true mode, 2.) solve a system of linear equations. There are a lot of good tools to do this, so implementing this is no sweat. And because you can rely on really fast, efficient methods that people have put a lot of work into, it turns out that this is pretty damn fast. So maybe you don’t need all the fancy machinery of variational inference or MCMC after all; “making do” never looked so fabulous.

