
In the previous post I argued that the second order approximation is useful for prediction. Let’s apply that to a model with links and see what happens. The random variable over which we take the expectation is now 
![\frac{1}{2}\mathrm{Cov}(\bar{z}_1 \circ \bar{z}_2) H(\mathbb{E}[\bar{z}_1 \circ \bar{z}_2]),](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Cmathrm%7BCov%7D%28%5Cbar%7Bz%7D_1+%5Ccirc+%5Cbar%7Bz%7D_2%29+H%28%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_1+%5Ccirc+%5Cbar%7Bz%7D_2%5D%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)

Let 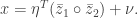



Now to compute the covariance. Observe that ![\mathbb{E}[\bar{z}_{1k} \bar{z}_{2k} \bar{z}_{1j} \bar{z}_{2j}] = \mathbb{E}[\bar{z}_{1k} \bar{z}_{1j}] \mathbb{E}[\bar{z}_{2k} \bar{z}_{2j}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7B1k%7D+%5Cbar%7Bz%7D_%7B2k%7D+%5Cbar%7Bz%7D_%7B1j%7D+%5Cbar%7Bz%7D_%7B2j%7D%5D+%3D+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7B1k%7D+%5Cbar%7Bz%7D_%7B1j%7D%5D+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7B2k%7D+%5Cbar%7Bz%7D_%7B2j%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)


![\mu^i_{kj} = \mathbb{E}[\bar{z}_{ik}]\mathbb{E}[\bar{z}_{ij}].](https://s0.wp.com/latex.php?latex=%5Cmu%5Ei_%7Bkj%7D+%3D+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7Bik%7D%5D%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7Bij%7D%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
I implemented this new approximation and here are the results.
| Inference method | Parameter estimation | Prediction method | Log likelihood (Higher is better) |
 |
Regularized optimization | first order |
-11.755 |
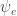 |
Regularized optimization | |
-11.6019 |
|
Fixed at 4,-3 | first order |
-11.5183 |
|
Fixed at 4,-3 | |
-11.4354 |
|
Fixed at 4,-3 | second order |
-11.5192 |
|
Fixed at 4,-3 | |
-11.4352 |
Suckitude. The only thing that really matters is
- Fix parameters.
- Use
The rest doesn’t matter. Why? It might help to look at the plots of the link probability functions. These are parameterized by 


Comparison of different link probability functions
Comparison of different link prediction functions (log)
The endpoints are the same but there’s a dip in the middle for 
So why not directly optimize the objective we care about?

