Suppose that I have the following model: 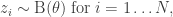
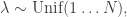 and
and 
 are hidden and
are hidden and  is observed. This model is perhaps not as facile as it seems; the
is observed. This model is perhaps not as facile as it seems; the  ‘s might be mixture components in a mixture model, i.e., you can imagine hanging other observations off of these variables.
‘s might be mixture components in a mixture model, i.e., you can imagine hanging other observations off of these variables.
Since are hidden, we usually resort to some sort of approximate inference mechanism. For the sake of argument, assume that we’ve managed to a.) estimate the parameters of the model (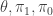 ) on some training set and b.) (approximately) compute the posteriors
) on some training set and b.) (approximately) compute the posteriors  and
and  for some test document using the other parts of the model which I’m purposefully glossing over. The question is, how do we make a prediction about on this test document using this information?
for some test document using the other parts of the model which I’m purposefully glossing over. The question is, how do we make a prediction about on this test document using this information?
Seems like an easy enough question; and for exposition’s sake I’m going to make this even easier. Assume that  . Now, to do the prediction we marginalize out the hidden variables
. Now, to do the prediction we marginalize out the hidden variables ![p(y) = \sum_{\vec{z}} \sum_\lambda p(y | \vec{z}, \lambda) p(\vec{z}) p(\lambda) = \mathbb{E}_{p(\vec{z})}[\sum_\lambda p (y | \vec{z}, \lambda) \frac{1}{N}].](https://s0.wp.com/latex.php?latex=p%28y%29+%3D+%5Csum_%7B%5Cvec%7Bz%7D%7D+%5Csum_%5Clambda+p%28y+%7C+%5Cvec%7Bz%7D%2C+%5Clambda%29+p%28%5Cvec%7Bz%7D%29+p%28%5Clambda%29+%3D+%5Cmathbb%7BE%7D_%7Bp%28%5Cvec%7Bz%7D%29%7D%5B%5Csum_%5Clambda+p+%28y+%7C+%5Cvec%7Bz%7D%2C+%5Clambda%29+%5Cfrac%7B1%7D%7BN%7D%5D.&bg=ffffff&fg=333333&s=0&c=20201002) By linearity, we can rewrite this as
By linearity, we can rewrite this as ![\pi_1 \mathbb{E}[\bar{z}] + \pi_0 (1 - \mathbb{E}[\bar{z}]),](https://s0.wp.com/latex.php?latex=%5Cpi_1+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D+%2B+%5Cpi_0+%281+-+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D%29%2C&bg=ffffff&fg=333333&s=0&c=20201002) where
where  And if, as usual, I wanted the log probabilities, those would be easy too,
And if, as usual, I wanted the log probabilities, those would be easy too, ![\log (\pi_1\mathbb{E}[\bar{z}] + \pi_0 ( 1 - \mathbb{E}[\bar{z}])).](https://s0.wp.com/latex.php?latex=%5Clog+%28%5Cpi_1%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D+%2B+%5Cpi_0+%28+1+-+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D%29%29.&bg=ffffff&fg=333333&s=0&c=20201002)
But suppose I were really nutter-butters and I decided to compute the log predictive likelihood another way, say by computing ![\mathbb{E}_\lambda[\mathbb{E}_{\vec{z}}[\log p(y | \vec{z}, \lambda)]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Clambda%5B%5Cmathbb%7BE%7D_%7B%5Cvec%7Bz%7D%7D%5B%5Clog+p%28y+%7C+%5Cvec%7Bz%7D%2C+%5Clambda%29%5D%5D&bg=ffffff&fg=333333&s=0&c=20201002) instead of
instead of ![\log \mathbb{E}_{\vec{z}}[\mathbb{E}_\lambda [p(y | \vec{z}, \lambda)]].](https://s0.wp.com/latex.php?latex=%5Clog+%5Cmathbb%7BE%7D_%7B%5Cvec%7Bz%7D%7D%5B%5Cmathbb%7BE%7D_%5Clambda+%5Bp%28y+%7C+%5Cvec%7Bz%7D%2C+%5Clambda%29%5D%5D.&bg=ffffff&fg=333333&s=0&c=20201002) It is worth pointing out that Jensen’s inequality tells us that the first term is a bound on the latter term. Because the
It is worth pointing out that Jensen’s inequality tells us that the first term is a bound on the latter term. Because the 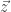 is a set of indicators, the log probability has a convenient form, namely
is a set of indicators, the log probability has a convenient form, namely 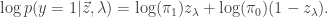 Applying the expectations yields
Applying the expectations yields ![\log (\pi_1) \mathbb{E}[\bar{z}] + \log(\pi_0) ( 1-\mathbb{E}[\bar{z}]).](https://s0.wp.com/latex.php?latex=%5Clog+%28%5Cpi_1%29+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D+%2B+%5Clog%28%5Cpi_0%29+%28+1-%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D%29.&bg=ffffff&fg=333333&s=0&c=20201002)
Jensen’s inequality is basically a statement about a first order Taylor approximation, i.e., ![\mathbb{E}[f(X)] \approx f(\mathbb{E}[X]),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%5Capprox+f%28%5Cmathbb%7BE%7D%5BX%5D%29%2C&bg=ffffff&fg=333333&s=0&c=20201002) when
when  is convex. When is this approximation good? We might attempt this by looking at the second order term. I will save you the arduous derivation:
is convex. When is this approximation good? We might attempt this by looking at the second order term. I will save you the arduous derivation: ![\log \mathbb{E}[p(y = 1 | \vec{z}, \lambda)] - \mathbb{E}[\log p(y = 1 | \vec{z}, \lambda)] \approx \frac{\pi_1 - \pi_0}{2 \pi_1 \mathbb{E}[\bar{z}] + 2 \pi_0 (1 - \mathbb{E}[\bar{z}])} \mathbb{E}[\bar{z}] (1 - \mathbb{E}[\bar{z}]).](https://s0.wp.com/latex.php?latex=%5Clog+%5Cmathbb%7BE%7D%5Bp%28y+%3D+1+%7C+%5Cvec%7Bz%7D%2C+%5Clambda%29%5D+-+%5Cmathbb%7BE%7D%5B%5Clog+p%28y+%3D+1+%7C+%5Cvec%7Bz%7D%2C+%5Clambda%29%5D+%5Capprox+%5Cfrac%7B%5Cpi_1+-+%5Cpi_0%7D%7B2+%5Cpi_1+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D+%2B+2+%5Cpi_0+%281+-+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D%29%7D+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D+%281+-+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D%29.&bg=ffffff&fg=333333&s=0&c=20201002)
Now what better accompaniment to an equation than a plot. I’ve plotted the 2nd order approximation to the difference (solid lines) and the true difference (dashed lines) for different values of  while keeping
while keeping 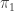 fixed at
fixed at 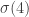 where
where  is the sigmoid function. The errors are plotted as functions of
is the sigmoid function. The errors are plotted as functions of ![\mathbb{E}[\bar{z}].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D.&bg=ffffff&fg=333333&s=0&c=20201002) I’ve also put a purple line at
I’ve also put a purple line at  that’s the actual log probability you’d see if your predictive model just guessed
that’s the actual log probability you’d see if your predictive model just guessed 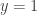 with probability 0.5.
with probability 0.5.
Moving the log into the expectation
First thing off the bat: the error is pretty large. For fairly reasonable settings of the parameters, the difference between the two predictive methods actually exceeds the error one would get just by guessing 50/50. For small values of ![\mathbb{E}[\bar{z}],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) the 2nd order approximation is pretty good, but for large values it greatly underestimates the error. Should I be worried (because, for example, moving the log around the expectation is a key step in EM, variational methods, etc.)?
the 2nd order approximation is pretty good, but for large values it greatly underestimates the error. Should I be worried (because, for example, moving the log around the expectation is a key step in EM, variational methods, etc.)?
I was motivated to do all this because of a previous post, in which I claimed that a certain approximation of a similar nature was good; the reason there was the low covariance or the random variable. Here, the covariance is large when the expectation is not close to either 0 or 1. Thus the second (and higher) order terms cannot be ignored. There are really two questions I want answered now:
- What happens if the random variable in this model is
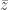 rather than ?
rather than ?
- What happens if the random variable in the earlier post is instead of ?


