
So in reading group today Chernoff bounds came up. The bound basically says that if we sample random variables and sum them we are very likely to be close to the expected sum. Estimating partition functions is a central challenge in many machine learning applications, so couldn’t we just sample and estimate the sum and have the bound guarantee that we’re not far off?
To wit, let 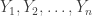


![P(S - \mathbb{E}[S] \ge n\epsilon) \le \exp(-\frac{2n\epsilon^2}{B}).](https://s0.wp.com/latex.php?latex=P%28S+-+%5Cmathbb%7BE%7D%5BS%5D+%5Cge+n%5Cepsilon%29+%5Cle+%5Cexp%28-%5Cfrac%7B2n%5Cepsilon%5E2%7D%7BB%7D%29.&bg=ffffff&fg=333333&s=0&c=20201002)
Now let us adapt this to estimating the partition function, 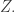


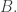
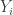

![\mathbb{E}[\mu(X_i)] = \frac{Z}{|\mathscr{X}|}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmu%28X_i%29%5D+%3D+%5Cfrac%7BZ%7D%7B%7C%5Cmathscr%7BX%7D%7C%7D.&bg=ffffff&fg=333333&s=0&c=20201002)


So let’s see what happens when we do things empirically. I randomly generated Ising models by sampling canonical parameters (using the standard overspecified representation) from a N(0, 1) distribution for both individual and pair parameters. In total, there were 40 nodes. I estimate the partition function (or rather, the partition function divided by 2^40) using the above technique and plot the estimate as a function of iteration over 300 iterations. I restarted the estimation 5 times to see if the different runs would converge to similar values. Attached are said plots for 2 different models (10 runs of 300 iterations total).
Monte carlo estimates of an Ising model partition function (1/2)
Monte carlo estimates of an Ising model partition function (2/2)
It seems like this estimate does horrendously. You might as well use a random number generator =). The key problem is that there are sudden jumps in our estimates. When there’s enough coupling in the model, the modes become very peaky. Another way of looking at it is by examining the bound on the right. Recall that this term depends on the bound on the measure, 
So there we have it, Hoeffding’s inequality can only be applied when there isn’t much coupling and the bound on the measure is small. As the bound increases, Hoeffding’s inequality gives us exponentially worse guarantees; unfortunately, the strongly coupled case is precisely the interesting case!


Testing latex comments: