
It is a good idea to always make sure to make experiments exactly reproducible. Sometimes in the heat of a paper deadline, a bunch of experiments are run with different parameter settings and what not and a few months down the road one might be hard pressed to remember exactly how you got those numbers. I’ve learned this the hard way so for the last few submissions I’ve always tried to make sure something in the CVS encodes the precise settings necessary.
Last night, while looking up what I did, I rediscovered that alpha is important sometimes. Not so much because of scale, but because of the distribution over topics it reports. My experience is that fitting alpha in an EM context rarely works; it either totally messes up your inference or it just reproduces the alpha that you fed in initially. But I did get into the habit of having the model fit and spit out alpha after the very last iteration of EM, just get some idea of what the topic distributions look like.
Usually you get something which is pretty uniform over your K topics. But sometimes you don’t. In old-fashioned LDA, this usually happens when you have too many topics. With models such as RTM, you can also get this effect because your graph manifold may have cliques of different sizes. In these cases, when you’re computing predictive word likelihood of an empty document, you are liable to perform much worse than baseline if you assume a symmetric Dirichlet prior rather than one which reflects the topic distribution on your training set.
![\mathbb{E}[\log p(y | z, z')] = y \mathbb{E}[x] - \mathbb{E}[\log(1 + \exp(x))],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clog+p%28y+%7C+z%2C+z%27%29%5D+%3D+y+%5Cmathbb%7BE%7D%5Bx%5D+-+%5Cmathbb%7BE%7D%5B%5Clog%281+%2B+%5Cexp%28x%29%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) where
where 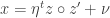 .
. , but for large
, but for large  . The solution that the delta method uses is to center it at the mean
. The solution that the delta method uses is to center it at the mean ![\mu = \mathbb{E}[x]](https://s0.wp.com/latex.php?latex=%5Cmu+%3D+%5Cmathbb%7BE%7D%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002) . But does this give us any real guarantee that we won’t be better off by centering it elsewhere?
. But does this give us any real guarantee that we won’t be better off by centering it elsewhere?  using settings typical of the corpora I look at. Turns out that the first order approximation at the mean is really good because the variance on z is really low when you have enough words.
using settings typical of the corpora I look at. Turns out that the first order approximation at the mean is really good because the variance on z is really low when you have enough words. ) thing not work as well as the “incorrect” (
) thing not work as well as the “incorrect” (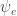 ) approximation?
) approximation?
