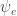The central challenge of variational methods is usually computing expectations of log probabilities. In the case of the RTM, this is ![\mathbb{E}[\log p(y | z, z')] = y \mathbb{E}[x] - \mathbb{E}[\log(1 + \exp(x))],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clog+p%28y+%7C+z%2C+z%27%29%5D+%3D+y+%5Cmathbb%7BE%7D%5Bx%5D+-+%5Cmathbb%7BE%7D%5B%5Clog%281+%2B+%5Cexp%28x%29%29%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
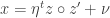
The first term is linear and so is easy enough, the second is problematic though. One approach is to use a Taylor approximation. The issue then becomes choosing the point around which to center the approximation. The partition function above really has two regimes: for small 

![\mu = \mathbb{E}[x]](https://s0.wp.com/latex.php?latex=%5Cmu+%3D+%5Cmathbb%7BE%7D%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
I couldn’t really answer this question analytically, so I decided to experiment. I sampled 
That of course brings up another question. Why does doing the “correct” (