
In the previous post, I showed how to compute the approximate objective function for regularization. I implemented such a harness in R with some real data from one of my runs to prototype it. Directly using nlm seems to work in fits and starts, perhaps because the optimization routine does not use gradients. The next step then is to compute the gradients. The gradient of the zero’th order term is 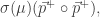


The second order term is where it gets hard. Taking the derivative by parts, we get 


I implement all this in R and it seems to converge erratically. Further more, the “converged” values perform worse than the not fitting at all. So to summarize results:
- Both
and
perform best without any M-Step fitting.
when the first is unfit but the second is fit.
when both are fit or both are unfit.
This is all very peculiar. In order to ameliorate the fitting process, I collapsed the parameter space so that 
In summary, it seems like across the board not fitting is still the best.
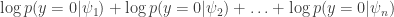 to the likelihood we wish to optimize, where
to the likelihood we wish to optimize, where  is drawn from a distribution of our choosing. Note that this becomes equivalent to
is drawn from a distribution of our choosing. Note that this becomes equivalent to ![\mathbb{E}[\log p(y = 0 | \psi)] = -\mathbb{E}[A(\eta^T \psi + nu)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clog+p%28y+%3D+0+%7C+%5Cpsi%29%5D+%3D+-%5Cmathbb%7BE%7D%5BA%28%5Ceta%5ET+%5Cpsi+%2B+nu%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where  . This is intractable to do exactly so we use the same old Taylor trick.
. This is intractable to do exactly so we use the same old Taylor trick. 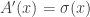 ,
,  ,
, 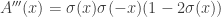 . The other thing we need is the variance of
. The other thing we need is the variance of  . Note that since variance is shift invariant, we can just compute the variance of
. Note that since variance is shift invariant, we can just compute the variance of  .
.  . Typically, covariance has two forms, one for when
. Typically, covariance has two forms, one for when  and when for when
and when for when  . For convenience, we will denote the first
. For convenience, we will denote the first  and the latter
and the latter  . Then this can be rewritten as
. Then this can be rewritten as  .
. 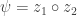 where
where  .
. ![C_{ij} = \mathbb{E}[z_{i} z_{j}]^2- p_i^2p_j^2](https://s0.wp.com/latex.php?latex=C_%7Bij%7D+%3D+%5Cmathbb%7BE%7D%5Bz_%7Bi%7D+z_%7Bj%7D%5D%5E2-+p_i%5E2p_j%5E2&bg=ffffff&fg=333333&s=0&c=20201002) .
. ![\mathbb{E}[z_i z_j ] = \mathrm{Cov}(z_i, z_j) + p_i p_j = -p_i p_j \frac{1}{\alpha + 1} + p_i p_j = \frac{\alpha}{\alpha + 1} p_i p_j.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bz_i+z_j+%5D+%3D+%5Cmathrm%7BCov%7D%28z_i%2C+z_j%29+%2B+p_i+p_j+%3D+-p_i+p_j+%5Cfrac%7B1%7D%7B%5Calpha+%2B+1%7D+%2B+p_i+p_j+%3D+%5Cfrac%7B%5Calpha%7D%7B%5Calpha+%2B+1%7D+p_i+p_j.&bg=ffffff&fg=333333&s=0&c=20201002) Consequently,
Consequently,  .
.![V_i = \mathbb{E}[z_i^2]^2 - p_{i}^4](https://s0.wp.com/latex.php?latex=V_i+%3D+%5Cmathbb%7BE%7D%5Bz_i%5E2%5D%5E2+-+p_%7Bi%7D%5E4&bg=ffffff&fg=333333&s=0&c=20201002) . Using common properties of the Dirichlet,
. Using common properties of the Dirichlet, ![\mathbb{E}[z_{i}^2] = \mathrm{Var}(z_i) + p_{i}^2 = \frac{p_i (1 - p_i)}{\alpha + 1} + p_{i}^2 = \frac{p_i (1 + \alpha p_i)}{\alpha + 1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bz_%7Bi%7D%5E2%5D+%3D+%5Cmathrm%7BVar%7D%28z_i%29+%2B+p_%7Bi%7D%5E2+%3D+%5Cfrac%7Bp_i+%281+-+p_i%29%7D%7B%5Calpha+%2B+1%7D+%2B+p_%7Bi%7D%5E2+%3D+%5Cfrac%7Bp_i+%281+%2B+%5Calpha+p_i%29%7D%7B%5Calpha+%2B+1%7D&bg=ffffff&fg=333333&s=0&c=20201002) . This yields
. This yields  .
.  .
.
