
Currently there are two regularization penalties, and this is sort of a hack. Ideally, we’d want to stick with one that is consistent across methods. This involves simulating additional non-links. In other words, we want to add 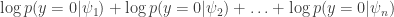

![\mathbb{E}[\log p(y = 0 | \psi)] = -\mathbb{E}[A(\eta^T \psi + nu)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clog+p%28y+%3D+0+%7C+%5Cpsi%29%5D+%3D+-%5Cmathbb%7BE%7D%5BA%28%5Ceta%5ET+%5Cpsi+%2B+nu%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)

This is very important: first-order is NOT enough. To see why this is, consider that what a first order approximation really says is that you can replace a set of points with their mean. Well, if you did this in logistic regression for all the 0’s and all the 1’s you’d get a single point for the 0’s and a single point for the 1’s, i.e., complete separability. And therefore your estimates will diverge.
So what are the ingredients to a second-order approximation? We first need to compute the gradients of the partition function: 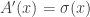

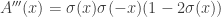


We can expand this by 





At this point we need to make about the distribution of 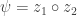

![C_{ij} = \mathbb{E}[z_{i} z_{j}]^2- p_i^2p_j^2](https://s0.wp.com/latex.php?latex=C_%7Bij%7D+%3D+%5Cmathbb%7BE%7D%5Bz_%7Bi%7D+z_%7Bj%7D%5D%5E2-+p_i%5E2p_j%5E2&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[z_i z_j ] = \mathrm{Cov}(z_i, z_j) + p_i p_j = -p_i p_j \frac{1}{\alpha + 1} + p_i p_j = \frac{\alpha}{\alpha + 1} p_i p_j.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bz_i+z_j+%5D+%3D+%5Cmathrm%7BCov%7D%28z_i%2C+z_j%29+%2B+p_i+p_j+%3D+-p_i+p_j+%5Cfrac%7B1%7D%7B%5Calpha+%2B+1%7D+%2B+p_i+p_j+%3D+%5Cfrac%7B%5Calpha%7D%7B%5Calpha+%2B+1%7D+p_i+p_j.&bg=ffffff&fg=333333&s=0&c=20201002)

On to the next term: ![V_i = \mathbb{E}[z_i^2]^2 - p_{i}^4](https://s0.wp.com/latex.php?latex=V_i+%3D+%5Cmathbb%7BE%7D%5Bz_i%5E2%5D%5E2+-+p_%7Bi%7D%5E4&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[z_{i}^2] = \mathrm{Var}(z_i) + p_{i}^2 = \frac{p_i (1 - p_i)}{\alpha + 1} + p_{i}^2 = \frac{p_i (1 + \alpha p_i)}{\alpha + 1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bz_%7Bi%7D%5E2%5D+%3D+%5Cmathrm%7BVar%7D%28z_i%29+%2B+p_%7Bi%7D%5E2+%3D+%5Cfrac%7Bp_i+%281+-+p_i%29%7D%7B%5Calpha+%2B+1%7D+%2B+p_%7Bi%7D%5E2+%3D+%5Cfrac%7Bp_i+%281+%2B+%5Calpha+p_i%29%7D%7B%5Calpha+%2B+1%7D&bg=ffffff&fg=333333&s=0&c=20201002)

Finally, notice that 

