
In the previous post, I showed how to compute the approximate objective function for regularization. I implemented such a harness in R with some real data from one of my runs to prototype it. Directly using nlm seems to work in fits and starts, perhaps because the optimization routine does not use gradients. The next step then is to compute the gradients. The gradient of the zero’th order term is 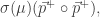


The second order term is where it gets hard. Taking the derivative by parts, we get 


I implement all this in R and it seems to converge erratically. Further more, the “converged” values perform worse than the not fitting at all. So to summarize results:
- Both
and
perform best without any M-Step fitting.
when the first is unfit but the second is fit.
when both are fit or both are unfit.
This is all very peculiar. In order to ameliorate the fitting process, I collapsed the parameter space so that 
In summary, it seems like across the board not fitting is still the best.

