
So one more wrinkle to add to the pile. I was wondering why a “better” method should fare worse. All the explorations below have only confirmed that. Well, there’s one other way (other than the E-step and the M-step) in which the two differ: prediction. The link predictions routines are different and link prediction is where the real performance differences are as well. In the case of 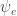
![\mathbb{E}[p(y_{ij} | z_i, z_j)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bp%28y_%7Bij%7D+%7C+z_i%2C+z_j%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[\log p(y_{ij} | z_i, z_j)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clog+p%28y_%7Bij%7D+%7C+z_i%2C+z_j%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
A different approach is used for 
Instead of answering this question directly, I ask another question; how much is gained by doing the right thing on 



Thanks alot – your answer solved all my problems after several days stugrlging