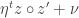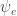Below I asked the question of why an approximation which is more accurate seems to be performing worse than one which is more haphazard. The two methods differ in two principal ways:
- The approximate gradient computed during the E-step.
- The optimization of the parameters in the M-step.
In the E-step they differ mainly in how they push a node’s topic distribution toward its neighbors’. With the simple but incorrect method, the gradient is proportional to 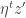
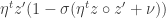
I futzed with the code to make it so that we push more like the incorrect method, but this didn’t seem to affect the results. I suspect that