
I was a little bit sneaky in my previous post and the reason I say this will become apparent when I change the function being approximated. Let’s break it down like this: there are three things we want to compare ![\log \mathbb{E}[f(x)] (1),](https://s0.wp.com/latex.php?latex=%5Clog+%5Cmathbb%7BE%7D%5Bf%28x%29%5D+%281%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![\log f(\mathbb{E}[x]) (2),](https://s0.wp.com/latex.php?latex=%5Clog+f%28%5Cmathbb%7BE%7D%5Bx%5D%29+%282%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[\log f(x)] (3).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clog+f%28x%29%5D+%283%29.&bg=ffffff&fg=333333&s=0&c=20201002)

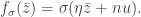
In the previous post, I focused on 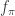
![\frac{1}{2}\mathrm{Var}(x)(\frac{f''(\mathbb{E}[x])}{f(\mathbb{E}[x])} - (\frac{f'(\mathbb{E}[x])}{f(\mathbb{E}[x])})^2).](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Cmathrm%7BVar%7D%28x%29%28%5Cfrac%7Bf%27%27%28%5Cmathbb%7BE%7D%5Bx%5D%29%7D%7Bf%28%5Cmathbb%7BE%7D%5Bx%5D%29%7D+-+%28%5Cfrac%7Bf%27%28%5Cmathbb%7BE%7D%5Bx%5D%29%7D%7Bf%28%5Cmathbb%7BE%7D%5Bx%5D%29%7D%29%5E2%29.&bg=ffffff&fg=333333&s=0&c=20201002)
Note that here we do much better than before. Except for a few errant cases we’re actually down almost an order of magnitude. We should be happy that we’ve got the problem licked. Ok, on to the next problem. Suppose we want to compare (1) and (2). Note that these are identical for 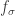
![\frac{1}{2}\mathrm{Var}(x)f''(\mathbb{E}[x]).](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Cmathrm%7BVar%7D%28x%29f%27%27%28%5Cmathbb%7BE%7D%5Bx%5D%29.&bg=ffffff&fg=333333&s=0&c=20201002)
Error using a 1st order predictive approximation
Error using a 2nd order predictive approximation
With a first order approximation, we get some pretty significant errors. Using the second order approximation greatly reduces those errors (by an order of magnitude). It seems like the 2nd order approximation is a good idea for this application. Now the question is, will more accuracy here lead to a better performing model on real data?

