
You know, I’ve always taken it for granted that what we want to do is probabilistic inference but lately I’ve been thinking more about what we really want and how to get there.
To illustrate my point, consider our dear friend LDA. For the uninitiated, let me write down the generative process for this Bayesian mixture model of discrete data:
- For
, draw
;
- For
:
- Draw
;
- For
:
- Draw
;
- Draw
.
- Draw
- Draw
We only observe 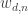


But in fact what we often care about is the mode. Just look at the way practitioners actually use these things. A typical MCMC experiment will run the updates for a hundred iterations or so, look at the final state of the parameters (under the assumption that we’ve found the mode) and then put a pretty picture of this final state in the paper.
If that’s what we actually want, why bother with the rest? Put another way, our goal is to maximize the joint likelihood of the data and the parameters we care about. One parameter we typically care about is 
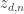
With these facts guiding us, we can write out the optimization problem for a particular document as 



The objective function, in total then, is 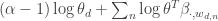
So how well does it do? To test this I generated a synthetic data set using what I felt were fairly typical hyperparameters: 



I then used the procedure above to estimate optimal values of 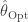
mode mean using 
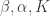
With these estimates of 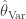
So what we’ve got here is a fairly fast and easy way of finding some kind of “mode” for LDA. Although the modes found by the two techniques aren’t really maximizing the same thing, they both tend to do equally well at recovering the true value of the parameters. So why not just optimize?
P.S. If anybody is actually reading this, and has tried doing optimization with constraints of this sort, we should trade war stories.


Hi,
I just stumbled upon your blog (and added it to my bookmarks 🙂
What you write here is really interesting, and resembles the cross-entropy method (a lengthy, but good introduction is here: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.89.1072&rep=rep1&type=pdf ). It starts out as an importance sampling-like method for estimating probabilities of rare events. this problem is then transformed to an optimization problem.
I used CEM quite a lot as a black-box optimization method for all sorts of problems, and it worked really well so far.
Hi Jonathan,
I believe that what you do is equivalent to Hoffman’s PLSA where you include a prior.
PLSA is a EM type algorithm to maximize the ML of the model to describe.
There’s definitely a tight connection here with pLSA. But as far as I know, the original EM algorithm for pLSA still computes expectations for each topic assignment in the E-step. Here we’re integrating those out and directly numerically estimating the per-document mixing proportions.
Hi Jonathan,
You’re the newest addition to my google reader. 🙂
Above, I believe you’re actually computing the *mean* of posterior approximated by LDA-C, rather than the mode. (Or at least you wrote the formula for the mean, not the mode, in your post.) I wonder if this has any effect on the overall result?
Hi,
Thanks for reading.
Good catch; I’m indeed computing the mean, not the mode (post updated)! Computing the mode is actually a little bit problematic using the parameters gleaned from LDA-C — if any of the parameters of a Dirichlet distribution are less than one, then the mode is going to be at one of the corners of the simplex which is not really conducive for the comparison above.
This suggests another subtle difference between the two techniques. At this late hour I don’t know how to do a “fair” comparison, but if you can concoct something, let me know.
Pingback: Jonathan’s Research Blog
Hi Jonathan,
Very interesting insight! But I still have one question here. In your post, you’re only trying to estimate $\theta$ given $\beta$. In reality, we need to estimate both. Can you method be used to estimate both parameters? I know we need to add the prior of $\beta$ to the objective function. Then how should we optimize our objective and get the optimal value of $\theta$ and $\beta$. I’m sorry I cannot figure it out as I don’t have a strong background in optimization.
In principle you could estimate both. This post is pretty old and subsequently the stochastic variational techniques suggested by Hoffman et al. which have a similar flavor suggest that this sort of join optimization could be very well the best way to train things.