
For those of you in Vancouver right now, here’s a shameless plug for our NIPS talk on interpreting topic models, which is happening at 4:10. Hope to see you there. And to whet your apetite, here’s a picture:

To find out what it means, come to the talk! And don’t forget the workshop on Friday =).
Come to our NIPS talk!
Filed under Uncategorized
Data for some topic model tasseography
Thanks to all of you who’ve expressed interest in and support for our recent paper Reading Tea Leaves: How Humans Interpret Topic Models, which was co-authored with Jordan Boyd-Graber, Sean Gerrish, Chong Wang, and David Blei. Many people (myself included) either implicitly or explicitly assume that topic models can find meaningful latent spaces with semantically coherent topics. The goal of this paper was to put this assumption to the test by gathering lots of human responses to some tasks we devised. We got some surprising and interesting results — held-out likelihood is often not a good proxy interpretability. You’ll have to read the paper for the details, but I’ll just leave you with a teaser plot below.

Furthermore, Jordan has worked hard prepping some of our data for public release. You can find that stuff here.
Filed under Uncategorized
LDA 1.1 is now on CRAN
Your favorite package for running topic models in R has been updated! This one not only has bugfixes and more utility functions, it also has two new models:
- The Networks Uncovered by Bayesian Inference (NUBBI) model which discovers connections between entities in free text (run
demo(nubbi), note that because of licensing reasons, I could not include the data for this demo in the package);
")
- the Relational Topic Model (RTM) for discovering patterns which account for both document content and connections between documents (run
demo(rtm)).
")
")
")
And because it’s on CRAN, everyone (including windows users) can install by simply executing install.packages("lda"). Please install, play with it, and let me know if you find any bugs.
Filed under Uncategorized
When is first-order better than second-order?
Dave and I were recently talking about Asuncion et al.’s wonderful recent paper “On Smoothing and Inference for Topic Models.” One thing that caught our eye was the CVB0 inference method for topic models, which is described as a first-order approximation of the collapsed variational Bayes approach. The odd thing is that this first-order approximation performs better than other, more “principled” approaches. I want to try to understand why. Here’s my current less-than-satisfactory stab:
Let me just lay out the problem. Suppose I want to approximate the marginal posterior over topic assignments 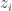


![p(z_i | w) = \mathbb{E}_{p(z_{-i} | w)}[p(z_i | z_{-i}, w)].](https://s0.wp.com/latex.php?latex=p%28z_i+%7C+w%29+%3D+%5Cmathbb%7BE%7D_%7Bp%28z_%7B-i%7D+%7C+w%29%7D%5Bp%28z_i+%7C+z_%7B-i%7D%2C+w%29%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
We can’t compute the expectation analytically, so we must turn to an approximate inference technique. One technique is to run a Gibbs sampler whence we get 

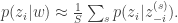
In the case of LDA, this conditional probability is proportional to

where
is the Dirichlet hyperparameter for topic proportion vectors;
is the Dirichlet hyperparameter for the topic multinomials;
-
is the number of times topic
has been assigned to word
-
is the number of times topic
-
is the number of times topic

Note that the above counts do not include the current value of
Instead of the Gibbs sampling approach, we could also approximate the expectation by taking a first order approximation (which we denote 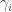
![\mathbb{E}[p(z_i | z_{-i})] \approx \gamma_i \propto \frac{\mathbb{E}[N^{\lnot i}_{wk}] + \eta}{\mathbb{E}[N^{\lnot i}_k] + V \eta} (\mathbb{E}[N^{\lnot i}_{dk}] + \alpha),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bp%28z_i+%7C+z_%7B-i%7D%29%5D+%5Capprox+%5Cgamma_i+%5Cpropto+%5Cfrac%7B%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_%7Bwk%7D%5D+%2B+%5Ceta%7D%7B%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_k%5D+%2B+V+%5Ceta%7D+%28%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_%7Bdk%7D%5D+%2B+%5Calpha%29%2C&bg=ffffff&fg=333333&s=0&c=20201002)
where the expectations are taken with respect to 

![\mathbb{E}[N^{\lnot i}_k] = \mathbb{E}[\sum_{j \ne i} z_{jk}] = \sum_{j \ne i} \mathbb{E}[z_{jk}] = \sum_{j \ne i} p(z_j) \approx \sum_{j \ne i} \gamma_j.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BN%5E%7B%5Clnot+i%7D_k%5D+%3D+%5Cmathbb%7BE%7D%5B%5Csum_%7Bj+%5Cne+i%7D+z_%7Bjk%7D%5D+%3D+%5Csum_%7Bj+%5Cne+i%7D+%5Cmathbb%7BE%7D%5Bz_%7Bjk%7D%5D+%3D+%5Csum_%7Bj+%5Cne+i%7D+p%28z_j%29+%5Capprox+%5Csum_%7Bj+%5Cne+i%7D+%5Cgamma_j.&bg=ffffff&fg=333333&s=0&c=20201002)
Thus, the solution to this approximation is exactly the CVB0 technique described in the paper. Note that I never directly introduced the concept of a variational distribution! CVB0 is simply a first-order approximation to the true expectations; in contrast, the second-order CVB approximation is an approximation of the variational expectations. So maybe that’s the answer to the puzzle: sometimes a first-order approximation to the true value is better than a second-order approximation to a surrogate objective.
Does anyone have any other explanations?
Filed under Uncategorized
R LDA package minor update: 1.0.1
Dave gently reminded me that properly assessing convergence of our models is important and that just running a sampler for N iterations is unsatisfactory. I agree wholeheartedly. As a first step, the collapsed Gibbs sampler in the R LDA package can now optionally report the log likelihood (to within a constant). For example, we can rerun the model fit in demo(lda) but with an extra flag set:
result <- lda.collapsed.gibbs.sampler(cora.documents,
K, ## Num clusters
cora.vocab,
25, ## Num iterations
0.1,
0.1,
compute.log.likelihood=TRUE)
Using the now-available variable result$log.likelihoods, we can plot the progress of the sampler versus iteration:

Grab it while it’s hot: http://www.cs.princeton.edu/~jcone/lda_1.0.1.tar.gz.
Filed under Uncategorized

