
The other day I paid a nice visit to Alex and Yan. We got around to talking about how bit.ly (a link shortener) can be used to track things on twitter. Anyhow, I’m sure they will blow you away with their analysis soon enough, but I thought I’d post some results from a really simple analysis.
The cool thing about bit.ly is that there’s an API that allows us to find out how many clickthrus there were on each link. This makes basic website analytics available to everyone and gives us the ability to start looking at what drives traffic. So we can try to figure out what motivates people to click on links posted on twitter: content, network, or something else?
Here’s what I did: I took the the last 3200 tweets by theonion and extracted all the bit.ly links therein (there were about 1200). I then got the number of clicks for each of the links as well as relevant metadata through the bit.ly API. There’s a tiny bit of noise there, but here’s what it looks like when I plot the number of clicks (as measured by bit.ly) versus the date when the link was tweeted:

You can see how phenomenal theonion’s twitter account has taken off in the last year, eventually reaching this weird cyclical pattern, a valley of which we currently seem to be in. (I don’t really have a good explanation for why that pattern is occurring.) But what’s also phenomenal is how closely clicks tend to track with the mean. That is, there isn’t a whole lot of variance at any given time. I’d guess that there is a set of regular readers who click on pretty much everything that theonion posts. And while there is an ebb and tide of regular readers, it’s not like within some time slice there are a few articles which really take off (“go viral”) and a bunch which languish. This is totally strange to me; my intuition based on diggs is that there’d be a polya-urn rich-get-richer type of distribution for link clickthrus but there doesn’t appear to be.
This is also strange to me because followers of this account are basically treating it like an RSS feed of onion articles, which makes me wonder: why are they using twitter at all?
I broke down the data a few other ways to see if I could tease out other trends. I tried breaking it down by time of day. And as expected posting stops at night and beings to pick up again at noon GMT = 8 am Eastern. But there isn’t a huge amount of variation based on when the urls get tweeted: once it gets into people’s queue it seems that they’ll get around to it eventually.

Finally, I tried breaking it down by day of the week. Not much news to report here. There are fewer tweets on Saturday and Sunday (although it sort of picked up on those days during July). And there isn’t any significant difference in terms of number of clickthrus per link on any given day of the week.

So there you have it. theonion has basically co-opted twitter as a news feed. And its readers faithfully read (or at least click on) the posted bit.ly links and any content or network effects seem to average out in the end.
Major thanks to Eytan for introducing me to the bit.ly API and lots of pro-tips on navigating/understanding the twitterverse.
 and the multinomial topic distributions
and the multinomial topic distributions  . Continuing along those lines, here I describe yet another way of doing so. This way turns out to be much faster, but at the cost of accuracy.
. Continuing along those lines, here I describe yet another way of doing so. This way turns out to be much faster, but at the cost of accuracy.  . The trick I want to use here is the concave bound, which lets me rewrite this function as
. The trick I want to use here is the concave bound, which lets me rewrite this function as  Solving this for
Solving this for  turns out to be easy:
turns out to be easy: 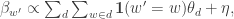 where
where  is a Dirichlet hyperparameter on
is a Dirichlet hyperparameter on  . The solution will always be degenerate at a corner of the simplex. While this is not necessarily bad for modeling likelihood, it does mean that we won’t be able to get a handle on mixed-membership behavior. An alternative is to optimize a slightly different bound: playing the same trick as before but with different variables yields:
. The solution will always be degenerate at a corner of the simplex. While this is not necessarily bad for modeling likelihood, it does mean that we won’t be able to get a handle on mixed-membership behavior. An alternative is to optimize a slightly different bound: playing the same trick as before but with different variables yields:  This has a solution of the form:
This has a solution of the form:  where
where  is a Dirichlet hyperpamater on
is a Dirichlet hyperpamater on 
