In an earlier post, I looked at a couple of different ways to estimate the parameters of a latent Dirichlet allocation (LDA) model, namely the topic mixing proportions  and the multinomial topic distributions
and the multinomial topic distributions  . Continuing along those lines, here I describe yet another way of doing so. This way turns out to be much faster, but at the cost of accuracy.
. Continuing along those lines, here I describe yet another way of doing so. This way turns out to be much faster, but at the cost of accuracy.
As I mentioned in the previous post, the objective we try to maximize is the log likelihood of the data, namely 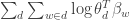 . The trick I want to use here is the concave bound, which lets me rewrite this function as
. The trick I want to use here is the concave bound, which lets me rewrite this function as  Solving this for
Solving this for  turns out to be easy:
turns out to be easy: 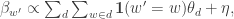 where
where  is a Dirichlet hyperparameter on .
is a Dirichlet hyperparameter on .
Now this bound isn’t as nice for solving for  . The solution will always be degenerate at a corner of the simplex. While this is not necessarily bad for modeling likelihood, it does mean that we won’t be able to get a handle on mixed-membership behavior. An alternative is to optimize a slightly different bound: playing the same trick as before but with different variables yields:
. The solution will always be degenerate at a corner of the simplex. While this is not necessarily bad for modeling likelihood, it does mean that we won’t be able to get a handle on mixed-membership behavior. An alternative is to optimize a slightly different bound: playing the same trick as before but with different variables yields:  This has a solution of the form:
This has a solution of the form:  where
where  is a Dirichlet hyperpamater on .
is a Dirichlet hyperpamater on .
So in essence what I’m proposing here is alternating between optimizing and , something which has a very EM flavor, except that each of the optimization steps really optimizes a different bound. Notice here that the “E-step” which optimizes is completely non-iterative — it’s just a simple sum-then-normalize — unlike variational inference for LDA which requires iterative estimation of the variational parameters for each E-step. This means that this simple procedure is liable to be much faster. I didn’t do any formal speed tests, but for the results below which were implemented in R, using this procedure to estimate the parameters of the model was noticeably faster than reading in the data! The same is decidedly NOT true for variational EM.
Ok, but how bad is the bound for getting us the true parameters? This bad. Here I’m showing you the barplots of the log KL distance between the estimated values of and the true values of used to generate this synthetic data set. Lower is better. “LDA” uses the mean estimates derived from the lda-c package. “Opti” uses the optimization procedure I described in the previous post (as mentioned there, “Opti” compares favorably with “LDA”). “Fast” uses the method I described here. “Fast” is rather worse than the other methods unfortunately. When looking at the results I noticed that “Fast” was considerably “smoother” than the other methods, i.e., “Fast” produces estimates with higher entropy. As an ad hoc fix, I also computed “Fast^2” which consists of the same estimates as “Fast”, but squared to yield sharper results. That one actually does better and is within shooting distance of the other methods, but it’s not quite there yet.
Anyways, there are a lot of scenarios where speed matters and in those cases I suspect “Fast” will turn out to be accurate enough and fast enough to be of practical use. “Fast^2” does better on this case, but I have no real understanding of why that’s so. Maybe it’s a fluke or maybe it’s the solution to a more accurate estimate of the log likelihood. And perhaps understanding why it’s doing better will help derive an even better way of estimating the parameters. Maybe one of you can enlighten me.


