
Every now and then someone (you know who you are) asks if the feature vectors one passes into LDA should be vectors of word counts (i.e., vectors of non-negative integers) or vectors of word presence/absence (i.e., vectors of binary values). Now the former gives strictly more information so the short answer is that you should always use word counts when available. But in my experience the difference is less than you might think.
To that end, I decided to put together a little side-by-side. Today’s corpus is Cora abstracts (with stopword and infrequent word filtering). I’m running everything through stock LDA-C with alpha set to 1.0 and K set to 10. Let me just preface what follows with the warning that your mileage may vary (and if it does, let me know!).
First up, let’s look at the topics (or specifically, the top 10 words in each topic) produced for the two feature representations. No earth-shattering differences here and absent an objective way to measure the quality of a topic, I’d be hard-pressed to say that one produced results any better than the other.
-
Word counts
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 learning problem performance model research control problems results models report state search classification data part reinforcement method paper bayesian technical paper selection methods analysis paper dynamic algorithms data probability grant system solution method markov university systems space classifier time supported simulation optimization parallel distribution science robot test application methods artificial Topic 6 Topic 7 Topic 8 Topic 9 Topic 10 network learning algorithm genetic knowledge neural decision error model system networks paper number evolutionary design input examples show fitness reasoning training features algorithms visual case weights algorithms class results theory recurrent algorithm learning population paper hidden rules results evolution systems trained approach function crossover cases output tree model strategies approach -
Word presence
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 system research performance learning algorithms behavior report paper data genetic systems abstract approach present search complex technical parallel classification algorithm design part proposed algorithm problem model paper implementation show results development university results training optimal paper science level accuracy show computational supported memory results problems environment computer multiple decision find Topic 6 Topic 7 Topic 8 Topic 9 Topic 10 method bayesian neural function learning methods reasoning network distribution paper problem models networks algorithm learn applied model input general problem problems cases learning class system time case model model reinforcement demonstrate paper hidden linear approach technique framework training functions knowledge large markov trained show learned learning knowledge weights results programming
Next, let’s look at the entropy of the topic multinomials to get an idea of what the general shape of these topic distributions look like. Here I’ve computed the topic entropies for both sides of the comparison; I then sort them by entropy (silly exchangeability!). Finally, I’m showing the scatter plot of the entropy of the word-counts topics vs. the entropy of the word-presence topics. The blue line runs along the diagonal. The differences are not too phenomenal; as expected binary features mean higher entropy since binary features amount to a smaller number of observations with which to overcome smoothing. But in the end these are really just 3-5% differences.
Next up, let’s look at convergence of the likelihood bound (these aren’t strictly comparable in any meaningful way since of course the likelihood is computed over two different data representations). Here I’m showing the variational bound on the log likelihood as a function of iteration. In black, word counts are used as features; in red, strictly binary features are used. Because the likelihood scales are different, I’ve rescaled the two curves so that they’re approximately equal (the two axes reflect the two original scales). As with the other evaluations, the shape of the two curves is very similar.
Finally, let’s look at the entropy of the per-document topic-proportions to get an idea of how topics are assigned in each case. As with the previous scatter plot, this plot shows the entropy of each document’s topic proportions under word counts vs. word presence. As before, less data in the binary feature case means generally higher entropy. But the differences are more notable in this case. While for many documents the differences are within 10% for some the difference is as large as 100%. This is most likely due to the fact that in some cases (e.g., when the number of distinct words in a document is small), feature binarization changes the character and amount of data in the document by quite a lot.
I think it is in these corner cases that using full word counts data is likely to be most useful. But overall I think the differences are not that great and not worth expending too many grey cells over.


The Dirichlet-Multinomial underlying LDA is deficient for binary data in the sense that it’s estimating probabilities for events that never occur (namely counts of terms in docs greater than one).
Have you thought about similar model structures that are more appropriate for binary data? I’m not sure how to do a multivariate-Bernoulli mixture. Instead of choosing a mixture component per token (as in LDA), you need to somehow choose one per binary decision, or per positive output or something.
You could generate the number of positive features per “document” and not model it (LDA doesn’t model count of tokens per doc). Then generate the positive outcomes in a “document” one at a time and adjusting subsequent estimates as you go. The problem here is that the choice of topic will depend on which features are still available to be chosen.
It’s not surprising your resulting discrete mixture components have higher entropy, because you’ve tamped down the non-uniformities that lower entropy (like all those “the” and “a” terms in English).
LDA’s not much better than naive Bayes in terms of modeling overdispersion, because you’re only finitely mixing topic multinomials. Something like a true beta-binomial (per term) or Dirichlet-multinomial would perhaps be better. That is, each topic isn’t a multinomial word generator, but a Dirichlet-multinomial word generator.
Thanks for the insightful comments.
I actually made an attempt to use a Bernoulli mixture (https://slycoder.wordpress.com/2009/03/03/a-generative-model-of-binary-data/) but it didn’t seem to work so well. Admittedly, I didn’t try very hard to make it work but that model seems to end up spending a lot of probability mass modeling the words/binary tokens that aren’t there which is often not a useful thing to capture.
The dispersion thing is an interesting idea. I’ve never tried anything like that before. Doing it on a per-document basis seems like it’d be pretty tractable to do. In essence:
For each document ,
, for each topic
for each topic  .
.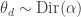 .
. for
for 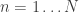 .
. for
for 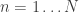 .
.
Draw
Draw topic proportions
Draw topic indicators
Draw words from
Is that what you had in mind? Have you actually implemented it?
Cool — that’s more or less what I was thinking as the obvious way to do the mixture. I didn’t think it’d work because of the negatives — it’s more problems with failed independence combined with low data counts. I clearly have some back-blog reading to do.
The less obvious approach is to somehow model a generator for the set. Maybe something like the Indian Buffet Process could be used, because it has the right intuitive “feel” for building up a set of choices from prior choices. The previous diners could be chosen and weighted by the document multinomial (itself still a Dirichlet variable).
As to the more dispersed form, no, I haven’t implemented it, but I’ve been meaning to do some per-term beta-binomial estimates for a while now. You often need lots of data to get a tight posterior on the variance, (expressed as the concentration or prior count sum(beta_k)), even when you can estimate the prior probalities tightly (beta_k/sum(beta_k)).
But if you’re using variational inference, it might be able to find the max more easily. With Gibbs sampling, the outlier variance estimates can also cause the chain to spin out of control. EM might even work if you add a prior to the variances to prevent the zero-variance blowups.
Yeah, it’s unlikely that one will be able to get good posterior estimates for gamma using 100 word observations dispersed over 100 V-dimensional vectors. But it’s probably worth a shot.
The IBP stuff is probably the “right” stuff to do in this case; the area is starting to get pretty well-trodden though =).
On the subject of IBPs and well-troddenness, didn’t Thibaux and Jordan make some relevant arguments on this subject in their hierarchical beta process/IBP paper? Their example application was document classification, where they got a moderate improvement over naive Bayes with binary present/not present features. No comparison to performance on counts features, though…
Since word occurrence is supposed to be bursty — when a word appears once, it begets itself appearing more times (i forget the reference for this) — this might not be too surprising. At least, that’s how I always understood the phenomenon of word presence giving similar models as word counts.
[Also: I just discovered this blog today. And of course, when I go in to comment somewhere, I find Bob Carpenter’s already commented! Is there *any* stats/ml/nlp blog he hasn’t already found?? 🙂 ]