
Audioscrobbler is this really cool data set from a few years ago; back then, Audioscrobbler had not yet been rolled into the last.fm but it had about the same functionality as it does now. Basically, it’s a little plugin for iTunes et al. that lets someone keep track of all the artists you listen to. The listening habits of several thousand people were collected and distributed under a creative commons license.
After some normalization/cleanup, we end up with a set of artists each user is liable to listen to.
This is the sort of co-occurrence statistic which Ising models are good at capturing. The Ising model contains a matrix of parameters which indicate the correlations between artists — that is, the relative likelihood that a given user will end up listening to both artists.
Because this is a rather high-dimensional problem, we can employ some L1 + L2 penalization; what we end up learning is a relatively sparse parameter matrix that is often easier to interpret.
With some magic (cough cough) we can learn this parameter matrix fairly quickly. I thought I’d post some of the correlations between artists here for your {be/a}musement.
Now the actual parameter matrix consists of several thousand artists. Here, I’m selecting the 10 artists with the highest total correlations. You might say that these are the artists which tug most fiercely on other artists (the most cliquey artists if you want). For each of these 10 artists, I show the 5 most highly correlated artists.
The results make pretty good sense; it’s actually kind of disturbing how predictable people’s musical tastes are. And for some reason the main cliques at the top of the list are all either metal bands or the sort of indie bands likely to populate OC soundtracks =). I should point out that if you go further down the list you eventually find a few other cliques such as trip hop (Portishead, Massive Attack, Lamb, Tricky, et al. [note to self: how cool would “et al.” be as a band name?]), 80s rock with remarkable staying power (Aerosmith, Bon Jovi, Guns N’ Roses), wuss rock (Counting Crows, DMB, Goo Goo Dolls), and just plain bad music (3DD, Hoobastank, Staind, Nickleback).
| Artist… | …is correlated with | ||||
| Metallica | Iron Maiden | Megadeth | Pantera | Slayer | Nightwish |
| In Flames | Dark Tranquillity | Soilwork | Children of Bodom | Arch Enemy | Dimmu Borgir |
| The Arcade Fire | The Fiery Furnaces | Broken Social Scene | The Go! Team | Bloc Party | Stars |
| Nightwish | Within Temptation | Sonata Arctica | Blind Guardian | Stratovarius | Therion |
| Rammstein | Nightwish | Apocalyptica | KoЯn | Marilyn Manson | Metallica |
| Belle and Sebastian | The Magnetic Fields | Neutral Milk Hotel | Yo La Tengo | Elliott Smith | Camera Obscura |
| Iron Maiden | Judas Priest | Iced Earth | Helloween | Manowar | Bruce Dickinson |
| Elliott Smith | Iron & Wine | The Decemberists | Bright Eyes | Sufjan Stevens | Belle and Sebastian |
| Bright Eyes | Rilo Kiley | Death Cab for Cutie | Desaparecidos | Cursive | The Good Life |
| Death Cab for Cutie | The Postal Service | Bright Eyes | The Shins | Rilo Kiley | Cursive |
 . The edges not allocated to the test set are allocated to the train set. The second hold-out method is “survey.” In this method, I go to each node and randomly select
. The edges not allocated to the test set are allocated to the train set. The second hold-out method is “survey.” In this method, I go to each node and randomly select  of the edges which have an endpoint at that node (or all of them if it has less than
of the edges which have an endpoint at that node (or all of them if it has less than 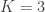 and
and 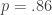 so that the number of edges in the train/test split is approximately the same between the two methods.
so that the number of edges in the train/test split is approximately the same between the two methods.  denote the
denote the  th outcome and
th outcome and  the score of the
the score of the 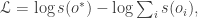 where
where  is the “good” outcome. For example, if we were searching for a needle in a haystack,
is the “good” outcome. For example, if we were searching for a needle in a haystack,  where
where  is the set of links of interest. When we use
is the set of links of interest. When we use 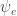 as the link probability function, we can evaluate this quantity analytically:
as the link probability function, we can evaluate this quantity analytically:  Here,
Here,  The last sum is could be computationally difficult, except that we can rewrite it as
The last sum is could be computationally difficult, except that we can rewrite it as  where
where  is the total number of possible links and
is the total number of possible links and  The gradient of this whole thing is easy enough to compute and we can throw the whole thing into our favorite optimizer using the log barrier method to ensure that
The gradient of this whole thing is easy enough to compute and we can throw the whole thing into our favorite optimizer using the log barrier method to ensure that  doesn’t run away.
doesn’t run away.  where we have put in the denominator
where we have put in the denominator  other outcomes which have the same response function as the outcome we care about. No matter what we think about those other outcomes, the objective can be optimized by setting the score for all of these outcomes as high as possible.
other outcomes which have the same response function as the outcome we care about. No matter what we think about those other outcomes, the objective can be optimized by setting the score for all of these outcomes as high as possible. 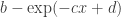
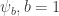

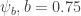



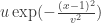



 and
and  and the second order term is then
and the second order term is then ![\frac{1}{2}\mathrm{Cov}(\bar{z}_1 \circ \bar{z}_2) H(\mathbb{E}[\bar{z}_1 \circ \bar{z}_2]),](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Cmathrm%7BCov%7D%28%5Cbar%7Bz%7D_1+%5Ccirc+%5Cbar%7Bz%7D_2%29+H%28%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_1+%5Ccirc+%5Cbar%7Bz%7D_2%5D%29%2C&bg=ffffff&fg=333333&s=0&c=20201002) where
where  is the Hessian matrix. We address each of these terms in turn.
is the Hessian matrix. We address each of these terms in turn. 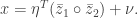 Then
Then  and
and  Consequently, the entries of the Hessian are
Consequently, the entries of the Hessian are 
![\mathbb{E}[\bar{z}_{1k} \bar{z}_{2k} \bar{z}_{1j} \bar{z}_{2j}] = \mathbb{E}[\bar{z}_{1k} \bar{z}_{1j}] \mathbb{E}[\bar{z}_{2k} \bar{z}_{2j}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7B1k%7D+%5Cbar%7Bz%7D_%7B2k%7D+%5Cbar%7Bz%7D_%7B1j%7D+%5Cbar%7Bz%7D_%7B2j%7D%5D+%3D+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7B1k%7D+%5Cbar%7Bz%7D_%7B1j%7D%5D+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7B2k%7D+%5Cbar%7Bz%7D_%7B2j%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) by independence. This can be rewritten as
by independence. This can be rewritten as  where
where  and
and ![\mu^i_{kj} = \mathbb{E}[\bar{z}_{ik}]\mathbb{E}[\bar{z}_{ij}].](https://s0.wp.com/latex.php?latex=%5Cmu%5Ei_%7Bkj%7D+%3D+%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7Bik%7D%5D%5Cmathbb%7BE%7D%5B%5Cbar%7Bz%7D_%7Bij%7D%5D.&bg=ffffff&fg=333333&s=0&c=20201002)

 and
and  We use a simplified model here where
We use a simplified model here where  I plot the values of the response against different values of this scalar.
I plot the values of the response against different values of this scalar. I suppose that although this function seems more “correct,” and is better able to lower the joint likelihood, the dip means that it is less aggressive in proposing positive links and is therefore worse at precision/recall type measures.
I suppose that although this function seems more “correct,” and is better able to lower the joint likelihood, the dip means that it is less aggressive in proposing positive links and is therefore worse at precision/recall type measures. 
